python使用Word2Vec進行情感分析解析
python實現情感分析(Word2Vec)
** 前幾天跟著老師做了幾個項目,老師寫的時候劈里啪啦一頓敲,寫了個啥咱也布吉島,線下自己就瞎琢磨,終于實現了一個最簡單的項目。輸入文本,然后分析情感,判斷出是好感還是反感。看最終結果:↓↓↓↓↓↓
1
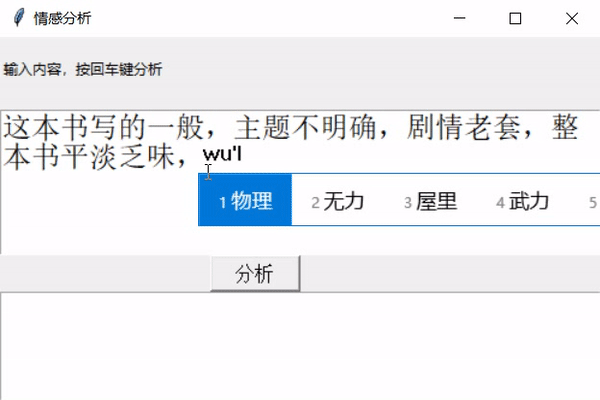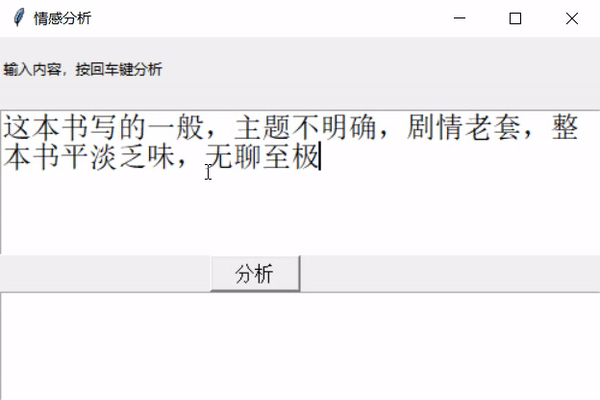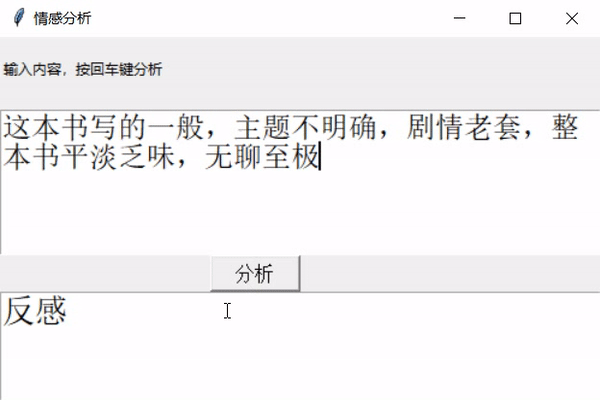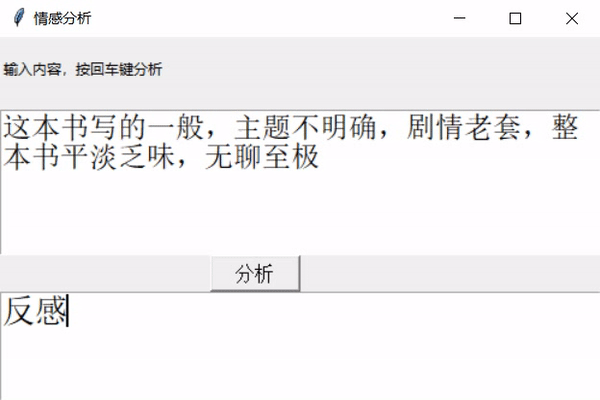 2
2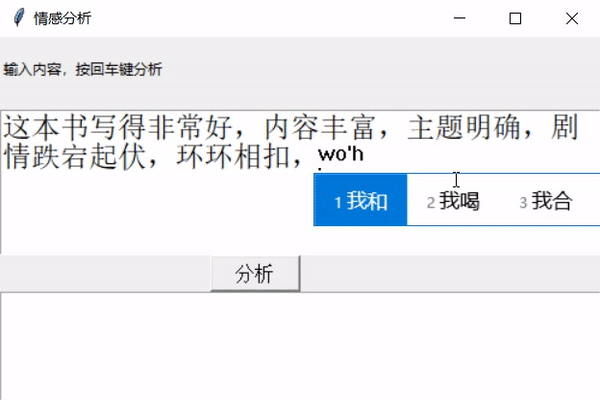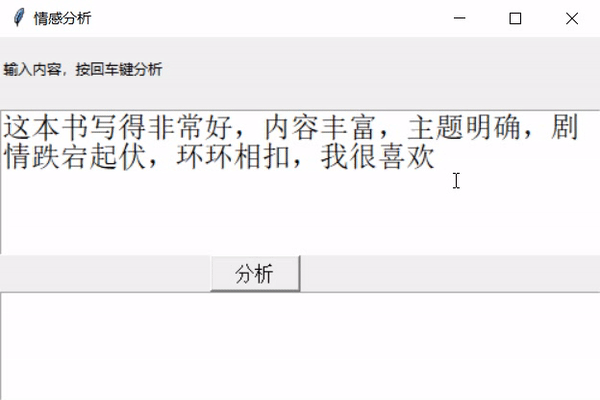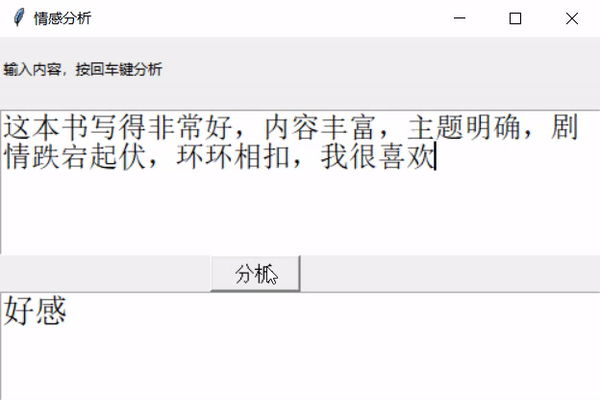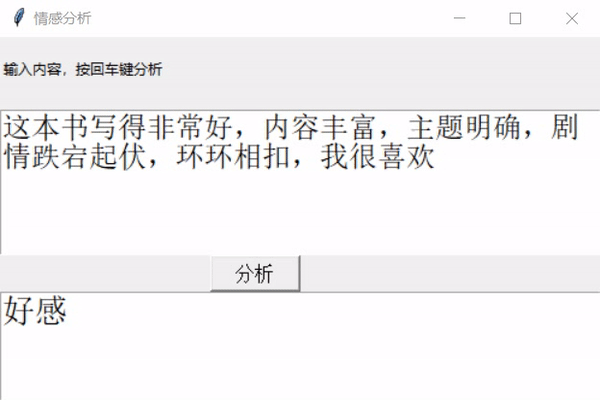
大概就是這樣,接下來實現一下。
實現步驟
加載數據,預處理
數據就是正反兩類,保存在neg.xls和pos.xls文件中,

數據內容類似購物網站的評論,分別有一萬多個好評和一萬多個差評,通過對它們的處理,變成我們用來訓練模型的特征和標記。
首先導入幾個python常見的庫,train_test_split用來對特征向量的劃分,numpy和pands是處理數據常見的庫,jieba庫用來分詞,joblib用來保存訓練好的模型,sklearn.svm是機器學習訓練模型常用的庫,我覺得核心的就是Word2Vec這個庫了,作用就是將自然語言中的字詞轉為計算機可以理解的稠密向量。
from sklearn.model_selection import train_test_splitimport numpy as npimport pandas as pdimport jieba as jbfrom sklearn.externals import joblibfrom sklearn.svm import SVCfrom gensim.models.word2vec import Word2Vec
加載數據,將數據分詞,將正反樣本拼接,然后創建全是0和全是1的向量拼接起來作為標簽,
neg =pd.read_excel('data/neg.xls',header=None,index=None) pos =pd.read_excel('data/pos.xls',header=None,index=None) # 這是兩類數據都是x值 pos[’words’] = pos[0].apply(lambda x:list(jb.cut(x))) neg[’words’] = neg[0].apply(lambda x:list(jb.cut(x))) #需要y值 0 代表neg 1代表是pos y = np.concatenate((np.ones(len(pos)),np.zeros(len(neg)))) X = np.concatenate((pos[’words’],neg[’words’]))
切分訓練集和測試集
利用train_test_split函數切分訓練集和測試集,test_size表示切分的比例,百分之二十用來測試,這里的random_state是隨機種子數,為了保證程序每次運行都分割一樣的訓練集和測試集。否則,同樣的算法模型在不同的訓練集和測試集上的效果不一樣。訓練集和測試集的標簽無非就是0和1,直接保存,接下來單獨處理特征向量。
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=3) #保存數據 np.save('data/y_train.npy',y_train) np.save('data/y_test.npy',y_test)
詞向量計算
網上搜到的專業解釋是這樣說的:使用一層神經網絡將one-hot(獨熱編碼)形式的詞向量映射到分布式形式的詞向量。使用了Hierarchical softmax, negative sampling等技巧進行訓練速度上的優化。作用:我們日常生活中使用的自然語言不能夠直接被計算機所理解,當我們需要對這些自然語言進行處理時,就需要使用特定的手段對其進行分析或預處理。使用one-hot編碼形式對文字進行處理可以得到詞向量,但是,由于對文字進行唯一編號進行分析的方式存在數據稀疏的問題,Word2Vec能夠解決這一問題,實現word embedding專業解釋的話我還是一臉懵,后來看了一個栗子,大概是這樣:word2vec也叫word embeddings,中文名“詞向量”,作用就是將自然語言中的字詞轉為計算機可以理解的稠密向量(Dense Vector)。在word2vec出現之前,自然語言處理經常把字詞轉為離散的單獨的符號,也就是One-Hot Encoder。

在語料庫中,杭州、上海、寧波、北京各對應一個向量,向量中只有一個值為1,其余都為0。但是使用One-Hot Encoder有以下問題。一方面,城市編碼是隨機的,向量之間相互獨立,看不出城市之間可能存在的關聯關系。其次,向量維度的大小取決于語料庫中字詞的多少。如果將世界所有城市名稱對應的向量合為一個矩陣的話,那這個矩陣過于稀疏,并且會造成維度災難。使用Vector Representations可以有效解決這個問題。Word2Vec可以將One-Hot Encoder轉化為低維度的連續值,也就是稠密向量,并且其中意思相近的詞將被映射到向量空間中相近的位置。如果將embed后的城市向量通過PCA降維后可視化展示出來,那就是這個樣子。

計算詞向量
#初始化模型和詞表 wv = Word2Vec(size=300,min_count=10) wv.build_vocab(x_train) # 訓練并建模 wv.train(x_train,total_examples=1, epochs=1) #獲取train_vecs train_vecs = np.concatenate([ build_vector(z,300,wv) for z in x_train]) #保存處理后的詞向量 np.save(’data/train_vecs.npy’,train_vecs) #保存模型 wv.save('data/model3.pkl') wv.train(x_test,total_examples=1, epochs=1) test_vecs = np.concatenate([build_vector(z,300,wv) for z in x_test]) np.save(’data/test_vecs.npy’,test_vecs)
•對句子中的所有詞向量取均值,來生成一個句子的vec
def build_vector(text,size,wv): #創建一個指定大小的數據空間 vec = np.zeros(size).reshape((1,size)) #count是統計有多少詞向量 count = 0 #循環所有的詞向量進行求和 for w in text: try: vec += wv[w].reshape((1,size)) count +=1 except: continue #循環完成后求均值 if count!=0: vec/=count return vec
訓練SVM模型
訓練就用SVM,sklearn庫已經封裝了具體的算法,只需要調用就行了,原理也挺麻煩,老師講課的時候我基本都在睡覺,這兒就不裝嗶了。(想裝裝不出來。。😭)
#創建SVC模型 cls = SVC(kernel='rbf',verbose=True) #訓練模型 cls.fit(train_vecs,y_train) #保存模型 joblib.dump(cls,'data/svcmodel.pkl') #輸出評分 print(cls.score(test_vecs,y_test))
預測
訓練完后也得到了訓練好的模型,基本這個項目已經完成了,然后為了使看起來好看,加了個圖形用戶界面,看起來有點逼格,
from tkinter import *import numpy as npimport jieba as jbimport joblibfrom gensim.models.word2vec import Word2Vecclass core(): def __init__(self,str): self.string=str def build_vector(self,text,size,wv): #創建一個指定大小的數據空間 vec = np.zeros(size).reshape((1,size)) #count是統計有多少詞向量 count = 0 #循環所有的詞向量進行求和 for w in text: try: vec += wv[w].reshape((1,size)) count +=1 except: continue #循環完成后求均值 if count!=0: vec/=count return vec def get_predict_vecs(self,words): # 加載模型 wv = Word2Vec.load('data/model3.pkl') #將新的詞轉換為向量 train_vecs = self.build_vector(words,300,wv) return train_vecs def svm_predict(self,string): # 對語句進行分詞 words = jb.cut(string) # 將分詞結果轉換為詞向量 word_vecs = self.get_predict_vecs(words) #加載模型 cls = joblib.load('data/svcmodel.pkl') #預測得到結果 result = cls.predict(word_vecs) #輸出結果 if result[0]==1: return '好感' else: return '反感' def main(self): s=self.svm_predict(self.string) return sroot=Tk()root.title('情感分析')sw = root.winfo_screenwidth()#得到屏幕寬度sh = root.winfo_screenheight()#得到屏幕高度ww = 500wh = 300x = (sw-ww) / 2y = (sh-wh) / 2-50root.geometry('%dx%d+%d+%d' %(ww,wh,x,y))# root.iconbitmap(’tb.ico’)lb2=Label(root,text='輸入內容,按回車鍵分析')lb2.place(relx=0, rely=0.05)txt = Text(root,font=('宋體',20))txt.place(rely=0.7, relheight=0.3,relwidth=1)inp1 = Text(root, height=15, width=65,font=('宋體',18))inp1.place(relx=0, rely=0.2, relwidth=1, relheight=0.4)def run1(): txt.delete('0.0',END) a = inp1.get(’0.0’,(END)) p=core(a) s=p.main() print(s) txt.insert(END, s) # 追加顯示運算結果def button1(event): btn1 = Button(root, text=’分析’, font=('',12),command=run1) #鼠標響應 btn1.place(relx=0.35, rely=0.6, relwidth=0.15, relheight=0.1) # inp1.bind('<Return>',run2) #鍵盤響應button1(1)root.mainloop()
運行一下:
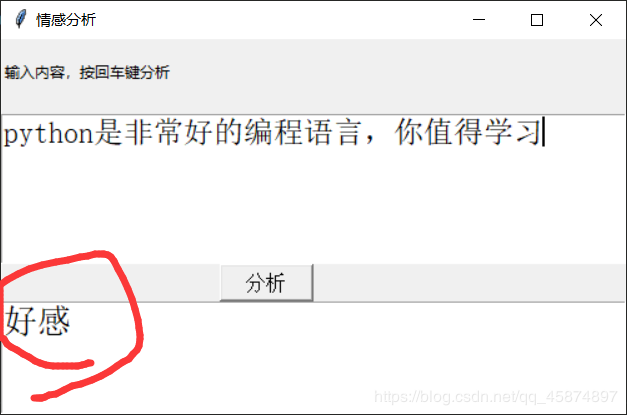
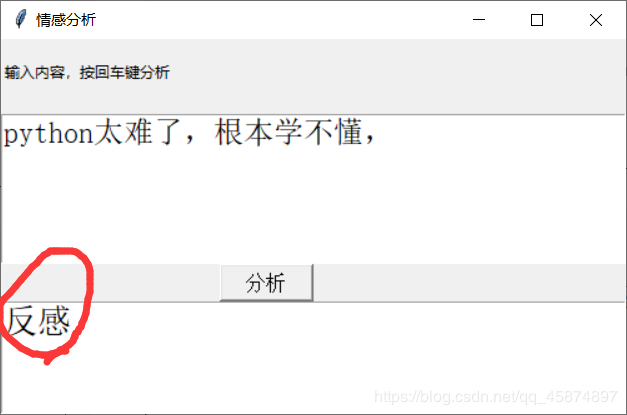
項目已經完成了,簡單的實現了一下情感分析,不過泛化能力一般般,輸入的文本風格類似與網上購物的評論那樣才看起來有點準確,比如喜歡,討厭,好,不好,質量,態度這些網店評論經常出現的詞匯分析起來會很準,但是例如溫柔,善良,平易近人這些詞匯分析的就會很差。優化的話我感覺可以訓練各種風格的樣本,或集成學習多個學習器進行分類,方法很多,但是實現起來又是一個大工程,像我這最后一排的學生,還是去打游戲去咯。
項目中的訓練樣本,訓練好的模型以及完整項目代碼↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
http://xiazai.jb51.net/202007/yuanma/data_jb51.rar
到此這篇關于python使用Word2Vec進行情感分析解析的文章就介紹到這了,更多相關python Word2Vec 情感分析 內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備