Apache Hive 通用調(diào)優(yōu)featch抓取機制 mr本地模式
目錄
- Apache Hive-通用優(yōu)化-featch抓取機制 mr本地模式
- Fetch抓取機制
- mapreduce本地模式
- 切換Hive的執(zhí)行引擎
- Apache Hive-通用優(yōu)化-join優(yōu)化
- - reduce端join
- -map端join
- reduce 端 join 優(yōu)化
- map 端 join 優(yōu)化
- Apache Hive--通用調(diào)優(yōu)--數(shù)據(jù)傾斜優(yōu)化
- group by數(shù)據(jù)傾斜
- join數(shù)據(jù)傾斜
- Apache Hive--通用調(diào)優(yōu)--MR程序task個數(shù)調(diào)整
- maptask個數(shù)
- reducetask個數(shù)
- 通用優(yōu)化-執(zhí)行計劃
- 通用優(yōu)化-并行機制,推測執(zhí)行機制
- Hive的嚴格模式
Apache Hive-通用優(yōu)化-featch抓取機制 mr本地模式
Fetch抓取機制
- 功能:在執(zhí)行sql的時候,能不走MapReduce程序處理就盡量不走MapReduce程序處理.
- 盡量直接去操作數(shù)據(jù)文件。
設(shè)置: hive.fetch.task.conversion= more。
--在下述3種情況下 sql不走mr程序--全局查找select * from student;--字段查找select num,name from student;--limit 查找select num,name from student limit 2;
mapreduce本地模式
- MapReduce程序除了可以提交到y(tǒng)arn集群分布式執(zhí)行之外,還可以使用本地模擬環(huán)境運行,當然此時就不是分布式執(zhí)行的程序,但是針對小文件小數(shù)據(jù)處理特別有效果。
- 用戶可以通過設(shè)置hive.exec.mode.local.auto的值為true,來讓Hive在適當?shù)臅r候自動啟動這個 優(yōu)化。
功能:如果非要執(zhí)行==MapReduce程序,能夠本地執(zhí)行的,盡量不提交yarn上執(zhí)行==。
默認是關(guān)閉的。意味著只要走MapReduce就提交yarn執(zhí)行。
mapreduce.framework.name = local 本地模式mapreduce.framework.name = yarn 集群模式
Hive提供了一個參數(shù),自動切換MapReduce程序為本地模式,如果不滿足條件,就執(zhí)行yarn模式。
set hive.exec.mode.local.auto = true;--3個條件必須都滿足 自動切換本地模式The total input size of the job is lower than: hive.exec.mode.local.auto.inputbytes.max (128MB by default) --數(shù)據(jù)量小于128MThe total number of map-tasks is less than: hive.exec.mode.local.auto.tasks.max (4 by default) --maptask個數(shù)少于4個The total number of reduce tasks required is 1 or 0. --reducetask個數(shù)是0 或者 1
切換Hive的執(zhí)行引擎
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
如果針對Hive的調(diào)優(yōu)依然無法滿足你的需求 還是效率低, 嘗試使用spark計算引擎 或者Tez.
Apache Hive-通用優(yōu)化-join優(yōu)化
在了解join優(yōu)化的時候,我們需要了解一個前置知識點:map端join 和reduce端join
- reduce端join
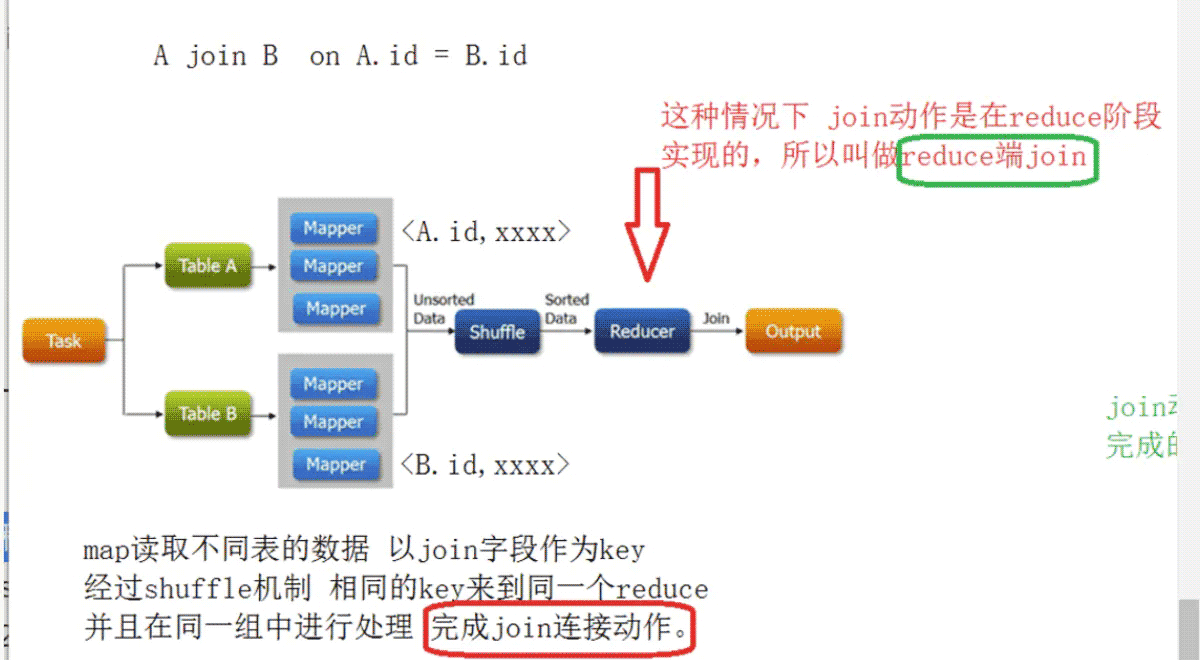
- 這種join的弊端在于map階段沒有承擔太多的責任,所有的數(shù)據(jù)在經(jīng)過shuffle在reduce階段實現(xiàn)的,而shuffle又是影響性能的核心點.
-map端join
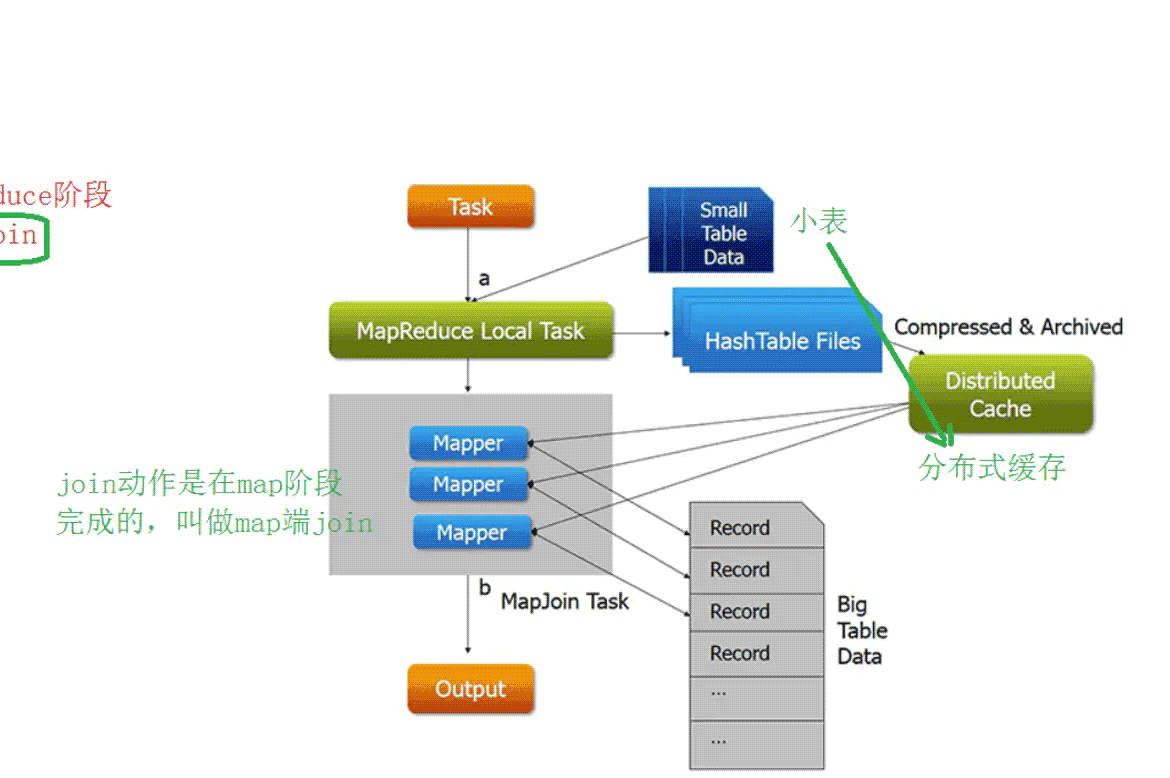
- 首先啟動本地任務(wù)將join中小表數(shù)據(jù)進行分布式緩存
- 啟動mr程序(只有map階段)并行處理大數(shù)據(jù),并且從自己的緩存中讀取小表數(shù)據(jù),進行join,結(jié)果直接輸出到文件中
- 沒有shuffle過程 也沒有reduce過程
- 弊端:緩存太小導(dǎo)致表數(shù)據(jù)不能太大
reduce 端 join 優(yōu)化
適合于大表Join大表
bucket join-- 適合于大表Join大表
方式1:Bucktet Map Join 分桶表
語法: clustered by colName(參與join的字段)
參數(shù): set hive.optimize.bucketmapjoin = true
要求: 分桶字段 = Join字段 ,分桶的個數(shù)相等或者成倍數(shù),必須是在map join中
方式2:Sort Merge Bucket Join(SMB)
基于有序的數(shù)據(jù)Join
語法:clustered by colName sorted by (colName)
參數(shù)
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
要求: 分桶字段 = Join字段 = 排序字段,分桶的個數(shù)相等或者成倍數(shù)
map 端 join 優(yōu)化
- hive.auto.convert.join.noconditionaltask
hive.auto.convert.join=trueHive老版本#如果參與的一個表大小滿足條件 轉(zhuǎn)換為map joinhive.mapjoin.smalltable.filesize=25000000 Hive2.0之后版本#是否啟用基于輸入文件的大小,將reduce join轉(zhuǎn)化為Map join的優(yōu)化機制。假設(shè)參與join的表(或分區(qū))有N個,如果打開這個參數(shù),并且有N-1個表(或分區(qū))的大小總和小于hive.auto.convert.join.noconditionaltask.size參數(shù)指定的值,那么會直接將join轉(zhuǎn)為Map join。hive.auto.convert.join.noconditionaltask=true hive.auto.convert.join.noconditionaltask.size=512000000
Apache Hive--通用調(diào)優(yōu)--數(shù)據(jù)傾斜優(yōu)化
數(shù)據(jù)傾斜優(yōu)化
什么是數(shù)據(jù)傾斜
描述的數(shù)據(jù)進行分布式處理 分配不平均的現(xiàn)象
數(shù)據(jù)傾斜的后果
某個task數(shù)據(jù)量過大 執(zhí)行時間過長 導(dǎo)致整體job任務(wù)遲遲不結(jié)束
執(zhí)行時間長 出bug及風險幾率提高
霸占運算資源 遲遲不釋放
通常如何發(fā)現(xiàn)數(shù)據(jù)傾斜
在yarn或者其他資源監(jiān)控軟件上 發(fā)現(xiàn)某個job作業(yè) 卡在某個進度遲遲不動 (注意 倒不是報錯)
造成數(shù)據(jù)傾斜的原因
數(shù)據(jù)本身就傾斜
自定義分區(qū)、分組規(guī)則不合理
業(yè)務(wù)影響 造成數(shù)據(jù)短期高頻波動
數(shù)據(jù)傾斜的通用解決方案
1、有錢 有預(yù)警
增加物理資源 單獨處理傾斜的數(shù)據(jù)
2、沒錢 沒有預(yù)警
傾斜數(shù)據(jù)打散 分步執(zhí)行
先將傾斜數(shù)據(jù)打散成多干份
處理的結(jié)果再最終合并
hive中數(shù)據(jù)傾斜的場景
場景一:group by 、count(distinct)
hive.map.aggr=true; map端預(yù)聚合
手動將數(shù)據(jù)隨機分區(qū) select * from table distribute by rand();
如果有數(shù)據(jù)傾斜問題 開啟負載均衡
先啟動第一個mr程序 把傾斜的數(shù)據(jù)隨機打散分散到各個reduce中
然后第二個mr程序把上一步結(jié)果進行最終匯總
hive.groupby.skewindata=true;
場景二:join
提前過濾,將大數(shù)據(jù)變成小數(shù)據(jù),實現(xiàn)Map Join
使用Bucket Join
使用Skew Join
將Map Join和Reduce Join進行合并,如果某個值出現(xiàn)了數(shù)據(jù)傾斜,就會將產(chǎn)生數(shù)據(jù)傾斜的數(shù)據(jù)單獨使用Map Join來實現(xiàn)
最終將Map Join的結(jié)果和Reduce Join的結(jié)果進行Union合并
Hive中通常指的是在reduce階段數(shù)據(jù)傾斜
解決方法
group by數(shù)據(jù)傾斜
方案一:開啟Map端聚合
hive.map.aggr=true;#是否在Hive Group By 查詢中使用map端聚合。#這個設(shè)置可以將頂層的部分聚合操作放在Map階段執(zhí)行,從而減輕清洗階段數(shù)據(jù)傳輸和Reduce階段的執(zhí)行時間,提升總體性能。但是指標不治本。
方案二:實現(xiàn)隨機分區(qū)
實現(xiàn)隨機分區(qū)select * from table distribute by rand();
方案三:數(shù)據(jù)傾斜時==自動負載均衡==只使用group by
hive.groupby.skewindata=true;#開啟該參數(shù)以后,當前程序會自動通過兩個MapReduce來運行#第一個MapReduce自動進行隨機分布到Reducer中,每個Reducer做部分聚合操作,輸出結(jié)果#第二個MapReduce將上一步聚合的結(jié)果再按照業(yè)務(wù)(group by key)進行處理,保證相同的分布到一起,最終聚合得到結(jié)果
join數(shù)據(jù)傾斜
- 方案一:提前過濾,將大數(shù)據(jù)變成小數(shù)據(jù),實現(xiàn)Map Join
- 方案二:使用Bucket Join
- 方案三:使用Skew Join
數(shù)據(jù)單獨使用Map Join來實現(xiàn)
#其他沒有產(chǎn)生數(shù)據(jù)傾斜的數(shù)據(jù)由Reduce Join來實現(xiàn),這樣就避免了Reduce Join中產(chǎn)生數(shù)據(jù)傾斜的問題#最終將Map Join的結(jié)果和Reduce Join的結(jié)果進行Union合并#開啟運行過程中skewjoinset hive.optimize.skewjoin=true;#如果這個key的出現(xiàn)的次數(shù)超過這個范圍set hive.skewjoin.key=100000;#在編譯時判斷是否會產(chǎn)生數(shù)據(jù)傾斜set hive.optimize.skewjoin.compiletime=true;set hive.optimize.union.remove=true;#如果Hive的底層走的是MapReduce,必須開啟這個屬性,才能實現(xiàn)不合并set mapreduce.input.fileinputformat.input.dir.recursive=true;
Apache Hive--通用調(diào)優(yōu)--MR程序task個數(shù)調(diào)整
maptask個數(shù)
- 如果是在MapReduce中 maptask是通過==邏輯切片==機制決定的。
- 但是在hive中,影響的因素很多。比如邏輯切片機制,文件是否壓縮、壓縮之后是否支持切割。
- 因此在==Hive中,調(diào)整MapTask的個數(shù),直接去HDFS調(diào)整文件的大小和個數(shù),效率較高==。
合并的大小最好=block size
如果大文件多,就調(diào)整blocl size
reducetask個數(shù)
- 如果在MapReduce中,通過代碼可以直接指定 job.setNumReduceTasks(N)
- 在Hive中,reducetask個數(shù)受以下幾個條件控制的
hive.exec.reducers.bytes.per.reducer=256000000
每個任務(wù)最大的 reduce 數(shù),默認為 1009
hive.exec.reducsers.max=1009
mapreduce.job.reduces
該值默認為-1,由 hive 自己根據(jù)任務(wù)情況進行判斷。--如果用戶用戶不設(shè)置 hive將會根據(jù)數(shù)據(jù)量或者sql需求自己評估reducetask個數(shù)。
--用戶可以自己通過參數(shù)設(shè)置reducetask的個數(shù)
set mapreduce.job.reduces = N
--用戶設(shè)置的不一定生效,如果用戶設(shè)置的和sql執(zhí)行邏輯有沖突,比如order by,在sql編譯期間,hive又會將reducetask設(shè)置為合理的個數(shù)。Number of reduce tasks determined at compile time: 1
通用優(yōu)化-執(zhí)行計劃
通過執(zhí)行計劃可以看出==hive接下來是如何打算執(zhí)行這條sql的==。
語法格式:explain + sql語句
通用優(yōu)化-并行機制,推測執(zhí)行機制
并行執(zhí)行機制
- 如果hivesql的底層某些stage階段可以并行執(zhí)行,就可以提高執(zhí)行效率。
- 前提是==stage之間沒有依賴== 并行的弊端是瞬時服務(wù)器壓力變大。
參數(shù)
set hive.exec.parallel=true; --是否并行執(zhí)行作業(yè)。適用于可以并行運行的 MapReduce 作業(yè),例如在多次插入期間移動文件以插入目標set hive.exec.parallel.thread.number=16; --最多可以并行執(zhí)行多少個作業(yè)。默認為8。
Hive的嚴格模式
- 注意。不要和動態(tài)分區(qū)的嚴格模式搞混淆。
- 這里的嚴格模式指的是開啟之后 ==hive會禁止一些用戶都影響不到的錯誤包括效率低下的操作==,不允許運行一些有風險的查詢。
設(shè)置
set hive.mapred.mode = strict --默認是嚴格模式 nonstrict
解釋
1、如果是分區(qū)表,沒有where進行分區(qū)裁剪 禁止執(zhí)行
2、order by語句必須+limit限制
推測執(zhí)行機制 ==建議關(guān)閉==。
- MapReduce中task的一個機制。
- 功能:
一個job底層可能有多個task執(zhí)行,如果某些拖后腿的task執(zhí)行慢,可能會導(dǎo)致最終job失敗。
所謂的==推測執(zhí)行機制就是通過算法找出拖后腿的task,為其啟動備份的task==。
兩個task同時處理一份數(shù)據(jù),誰先處理完,誰的結(jié)果作為最終結(jié)果。
- 推測執(zhí)行機制默認是開啟的,但是在企業(yè)生產(chǎn)環(huán)境中==建議關(guān)閉==。
以上就是Apache Hive 通用調(diào)優(yōu)featch抓取機制 mr本地模式的詳細內(nèi)容,更多關(guān)于Apache Hive 通用調(diào)優(yōu)的資料請關(guān)注其它相關(guān)文章!
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備