Python機器學(xué)習(xí)之AdaBoost算法
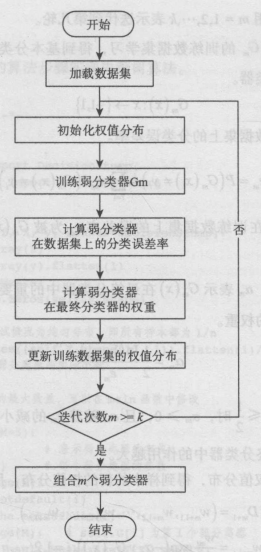
1.初始化訓(xùn)練數(shù)據(jù)的權(quán)值分布,每一個訓(xùn)練樣本最開始時都被賦予相同的權(quán)值 1/n
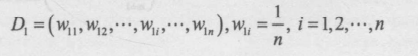
2.進行多輪迭代,用 m = 1,2,…,k 表示迭代到第幾輪
3.使用具有權(quán)值分布 Gm 的訓(xùn)練數(shù)據(jù)集學(xué)習(xí),得到基本分類器
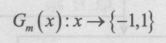
4.計算 Gm(x) 在訓(xùn)練數(shù)據(jù)集上的分類誤差率
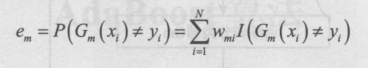
5.計算 Gm(x) 的系數(shù),am表示 Gm(x) 在最終分類器中的重要程度
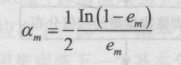
6.更新訓(xùn)練數(shù)據(jù)集的權(quán)值分布,得到樣本的新的權(quán)值分布,用于下一輪迭代
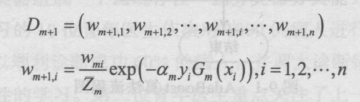
7.組合各個弱分類器
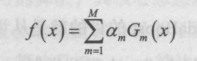
from numpy import *import matplotlib.pyplot as plt# 加載數(shù)據(jù)集def loadDataSet(fileName): numFeat = len(open(fileName).readline().split(’t’)) dataMat = [] labelMat = [] fr = open(fileName) for line in fr.readlines():lineArr = []curLine = line.strip().split(’t’)for i in range(numFeat - 1): lineArr.append(float(curLine[i]))dataMat.append(lineArr)labelMat.append(float(curLine[-1])) return dataMat, labelMat# 返回分類預(yù)測結(jié)果 根據(jù)閾值所以有兩種返回情況def stumpClassify(dataMatrix, dimen, threshVal, threshIneq): retArray = ones((shape(dataMatrix)[0], 1)) if threshIneq == ’lt’:retArray[dataMatrix[:, dimen] <= threshVal] = -1.0 else:retArray[dataMatrix[:, dimen] > threshVal] = -1.0 return retArray# 返回 該弱分類器單層決策樹的信息 更新D向量的錯誤率 更新D向量的預(yù)測目標(biāo)def buildStump(dataArr, classLabels, D): dataMatrix = mat(dataArr) labelMat = mat(classLabels).T m, n = shape(dataMatrix) numSteps = 10.0 bestStump = {} # 字典用于保存每個分類器信息 bestClasEst = mat(zeros((m, 1))) minError = inf # 初始化最小誤差最大 for i in range(n): # 特征循環(huán) (三層循環(huán),遍歷所有的可能性)rangeMin = dataMatrix[:, i].min()rangeMax = dataMatrix[:, i].max()stepSize = (rangeMax - rangeMin) / numSteps # (大-小)/分割數(shù) 得到最小值到最大值需要的每一段距離for j in range(-1, int(numSteps) + 1): # 遍歷步長 最小值到最大值的需要次數(shù) for inequal in [’lt’, ’gt’]: # 在大于和小于之間切換threshVal = (rangeMin + float(j) * stepSize) # 最小值+次數(shù)*步長 每一次從最小值走的長度predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal) # 最優(yōu)預(yù)測目標(biāo)值 用于與目標(biāo)值比較得到誤差errArr = mat(ones((m, 1)))errArr[predictedVals == labelMat] = 0weightedError = D.T * errArrif weightedError < minError: # 選出最小錯誤的那個特征 minError = weightedError # 最小誤差 后面用來更新D權(quán)值的 bestClasEst = predictedVals.copy() # 最優(yōu)預(yù)測值 bestStump[’dim’] = i # 特征 bestStump[’thresh’] = threshVal # 到最小值的距離 (得到最優(yōu)預(yù)測值的那個距離) bestStump[’ineq’] = inequal # 大于還是小于 最優(yōu)距離為-1 return bestStump, minError, bestClasEst# 循環(huán)構(gòu)建numIt個弱分類器def adaBoostTrainDS(dataArr, classLabels, numIt=40): weakClassArr = [] # 保存弱分類器數(shù)組 m = shape(dataArr)[0] D = mat(ones((m, 1)) / m) # D向量 每條樣本所對應(yīng)的一個權(quán)重 aggClassEst = mat(zeros((m, 1))) # 統(tǒng)計類別估計累積值 for i in range(numIt):bestStump, error, classEst = buildStump(dataArr, classLabels, D)alpha = float(0.5 * log((1.0 - error) / max(error, 1e-16)))bestStump[’alpha’] = alphaweakClassArr.append(bestStump) # 加入單層決策樹# 得到運算公式中的向量+/-α,預(yù)測正確為-α,錯誤則+α。每條樣本一個α# multiply對應(yīng)位置相乘 這里很聰明,用-1*真實目標(biāo)值*預(yù)測值,實現(xiàn)了錯誤分類則-,正確則+expon = multiply(-1 * alpha * mat(classLabels).T, classEst)D = multiply(D, exp(expon)) # 這三步為更新概率分布D向量 拆分開來了,每一步與公式相同D = D / D.sum()# 計算停止條件錯誤率=0 以及計算每次的aggClassEst類別估計累計值aggClassEst += alpha * classEst# 很聰明的計算方法 計算得到錯誤的個數(shù),向量中為1則錯誤值aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T, ones((m, 1))) # sign返回數(shù)值的正負(fù)符號,以1、-1表示errorRate = aggErrors.sum() / m # 錯誤個數(shù)/總個數(shù)# print('錯誤率:', errorRate)if errorRate == 0.0: break return weakClassArr, aggClassEst# 預(yù)測 累加 多個弱分類器獲得預(yù)測值*該alpha 得到結(jié)果def adaClassify(datToClass, classifierArr): # classifierArr是元組,所以在取值時需要注意 dataMatrix = mat(datToClass) m = shape(dataMatrix)[0] aggClassEst = mat(zeros((m, 1))) # 循環(huán)所有弱分類器 for i in range(len(classifierArr[0])):# 獲得預(yù)測結(jié)果classEst = stumpClassify(dataMatrix, classifierArr[0][i][’dim’], classifierArr[0][i][’thresh’], classifierArr[0][i][’ineq’])# 該分類器α*預(yù)測結(jié)果 用于累加得到最終的正負(fù)判斷條件aggClassEst += classifierArr[0][i][’alpha’] * classEst # 這里就是集合所有弱分類器的意見,得到最終的意見 return sign(aggClassEst) # 提取數(shù)據(jù)符號# ROC曲線,類別累計值、目標(biāo)標(biāo)簽def plotROC(predStrengths, classLabels): cur = (1.0, 1.0) # 每次畫線的起點游標(biāo)點 ySum = 0.0 # 用于計算AUC的值 矩形面積的高度累計值 numPosClas = sum(array(classLabels) == 1.0) # 所有真實正例 確定了在y坐標(biāo)軸上的步進數(shù)目 yStep = 1 / float(numPosClas) # 1/所有真實正例 y軸上的步長 xStep = 1 / float(len(classLabels) - numPosClas) # 1/所有真實反例 x軸上的步長 sortedIndicies = predStrengths.argsort() # 獲得累計值向量從小到大排序的下表index [50,88,2,71...] fig = plt.figure() fig.clf() ax = plt.subplot(111) # 循環(huán)所有的累計值 從小到大 for index in sortedIndicies.tolist()[0]:if classLabels[index] == 1.0: delX = 0 # 若為一個真正例,則沿y降一個步長,即不斷降低真陽率; delY = yStep # 若為一個非真正例,則沿x退一個步長,尖笑陽率else: delX = xStep delY = 0 ySum += cur[1] # 向下移動一次,則累計一個高度。寬度不變,我們只計算高度ax.plot([cur[0], cur[0] - delX], [cur[1], cur[1] - delY], c=’b’) # 始終會有一個點是沒有改變的cur = (cur[0] - delX, cur[1] - delY) ax.plot([0, 1], [0, 1], ’b--’) plt.xlabel(’False positive rate’) plt.ylabel(’True positive rate’) plt.title(’ROC curve for AdaBoost horse colic detection system’) ax.axis([0, 1, 0, 1]) plt.show() print('the Area Under the Curve is: ', ySum * xStep) # AUC面積我們以 高*低 的矩形來計算# 測試正確率datArr, labelArr = loadDataSet(’horseColicTraining2.txt’)classifierArr = adaBoostTrainDS(datArr, labelArr, 15)testArr, testLabelArr = loadDataSet(’horseColicTest2.txt’)prediction10 = adaClassify(testArr, classifierArr)errArr = mat(ones((67, 1))) # 一共有67個樣本cnt = errArr[prediction10 != mat(testLabelArr).T].sum()print(cnt / 67)# 畫出ROC曲線datArr, labelArr = loadDataSet(’horseColicTraining2.txt’)classifierArray, aggClassEst = adaBoostTrainDS(datArr, labelArr, 10)plotROC(aggClassEst.T, labelArr)五、算法優(yōu)化 權(quán)值更新方法的改進
在實際訓(xùn)練過程中可能存在正負(fù)樣本失衡的問題,分類器會過于關(guān)注大容量樣本,導(dǎo)致分類器不能較好地完成區(qū)分小樣本的目的。此時可以適度增大小樣本的權(quán)重使重心達到平衡。在實際訓(xùn)練中還會出現(xiàn)困難樣本權(quán)重過高而發(fā)生過擬合的問題,因此有必要設(shè)置困難樣本分類的權(quán)值上限。
訓(xùn)練方法的改進AdaBoost算法由于其多次迭代訓(xùn)練分類器的原因,訓(xùn)練時間一般會比別的分類器長。對此一般可以采用實現(xiàn)AdaBoost的并行計算或者訓(xùn)練過程中動態(tài)剔除掉權(quán)重偏小的樣本以加速訓(xùn)練過程。
多算法結(jié)合的改進除了以上算法外,AdaBoost還可以考慮與其它算法結(jié)合產(chǎn)生新的算法,如在訓(xùn)練過程中使用SVM算法加速挑選簡單分類器來替代原始AdaBoost中的窮舉法挑選簡單的分類器。
到此這篇關(guān)于Python機器學(xué)習(xí)之AdaBoost算法的文章就介紹到這了,更多相關(guān)Python AdaBoost算法內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備