詳解Bagging算法的原理及Python實現
集成學習是一種技術框架,它本身不是一個單獨的機器學習算法,而是通過構建并結合多個機器學習器來完成學習任務,一般結構是:先產生一組“個體學習器”,再用某種策略將它們結合起來,目前,有三種常見的集成學習框架(策略):bagging,boosting和stacking
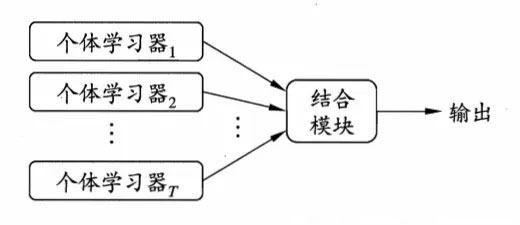
也就是說,集成學習有兩個主要的問題需要解決,第一是如何得到若干個個體學習器,第二是如何選擇一種結合策略,將這些個體學習器集合成一個強學習器
集成學習是指將若干弱分類器組合之后產生一個強分類器。弱分類器(weak learner)指那些分類準確率只稍好于隨機猜測的分類器(error rate < 50%)。如今集成學習有兩個流派,一種是bagging流派,它的特點是各個弱學習器之間沒有依賴關系,可以并行擬合,隨機森林算法就屬于bagging派系;另一個是boosting派系,它的特點是各個弱學習器之間有依賴關系,Adaboost算法就屬于boosting派系。在實現集成學習算法時,很重要的一個核心就是如何實現數據的多樣性,從而實現弱分類器的多樣性
集成學習有如下的特點:
(1)將多個分類方法聚集在一起,以提高分類的準確率(這些算法可以是不同的算法,也可以是相同的算法。);
(2)集成學習法由訓練數據構建一組基分類器,然后通過對每個基分類器的預測進行投票來進行分類;
(3)嚴格來說,集成學習并不算是一種分類器,而是一種分類器結合的方法;
(4)通常一個集成分類器的分類性能會好于單個分類器;
(5)如果把單個分類器比作一個決策者的話,集成學習的方法就相當于多個決策者共同進行一項決策。
Bagging和Boosting的使用區別如下:
1)樣本選擇:Bagging:訓練集是在原始集中有放回選取的,從原始集中選出的各輪訓練集之間是獨立的。Boosting:每一輪的訓練集不變,只是訓練集中每個樣例在分類器中的權重發生變化。而權值是根據上一輪的分類結果進行調整。
2)樣例權重Bagging:使用均勻取樣,每個樣例的權重相等Boosting:根據錯誤率不斷調整樣例的權值,錯誤率越大則權重越大。
3)預測函數Bagging:所有預測函數的權重相等。Boosting:每個弱分類器都有相應的權重,對于分類誤差小的分類器會有更大的權重。
4)并行計算Bagging:各個預測函數可以并行生成Boosting:各個預測函數只能順序生成,因為后一個模型參數需要前一輪模型的結果。
5)計算效果Bagging主要減小了variance,而Boosting主要減小了bias,而這種差異直接推動結合Bagging和Boosting的MultiBoosting的誕生
二、Bagging算法Bagging(裝袋算法)的集成學習方法非常簡單,假設我們有一個數據集D,使用Bootstrap sample(有放回的隨機采樣,這里說明一下,有放回抽樣是抽一個就放回一個,然后再抽,而不是這個人抽10個,再放回,下一個繼續抽,它是每一個樣本被抽中概率符合均勻分布)的方法取了k個數據子集(子集樣本數都相等):D1,D2,…,Dk,作為新的訓練集,我們使用這k個子集分別訓練一個分類器(使用分類、回歸等算法),最后會得到k個分類模型。我們將測試數據輸入到這k個分類器,會得到k個分類結果,比如分類結果是0和1,那么這k個結果中誰占比最多,那么預測結果就是誰。
大致過程如下:
1.對于給定的訓練樣本S,每輪從訓練樣本S中采用有放回抽樣(Booststraping)的方式抽取M個訓練樣本,共進行n輪,得到了n個樣本集合,需要注意的是這里的n個訓練集之間是相互獨立的。
2.在獲取了樣本集合之后,每次使用一個樣本集合得到一個預測模型,對于n個樣本集合來說,我們總共可以得到n個預測模型。
3.如果我們需要解決的是分類問題,那么我們可以對前面得到的n個模型采用投票的方式得到分類的結果,對于回歸問題來說,我們可以采用計算模型均值的方法來作為最終預測的結果。

那么我們什么時候該使用bagging集成方法:學習算法不穩定:就是說如果訓練集稍微有所改變就會導致分類器性能比較大大變化那么我們可以采用bagging這種集成方法AdaBoost只適用于二分類任務不同,Bagging可以用于多分類,回歸的任務舉個例子可以看出bagging的好處:X 表示一維屬性,Y 表示類標號(1或-1)測試條件:當x<=k時,y=?;當x>k時,y=?;k為最佳分裂點下表為屬性x對應的唯一正確的y類別:

每一輪隨機抽樣后,都生成一個分類器。然后再將五輪分類融合
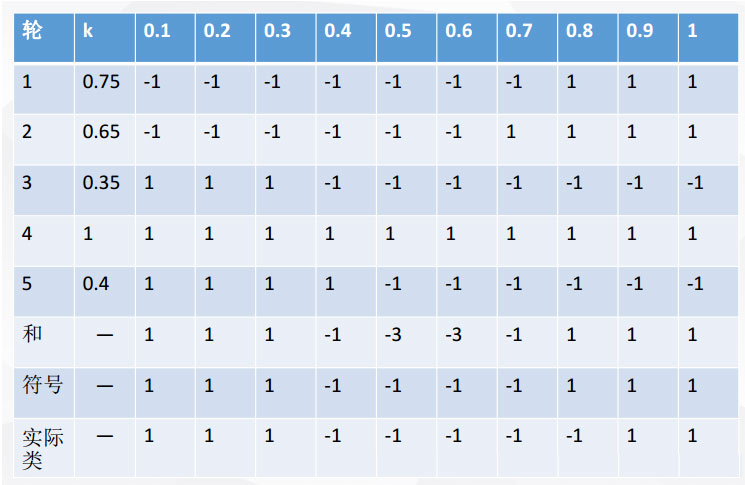
即是說當我們模型拿捏不住樣本屬于哪個,或者是分裂時的閾值,我們多做幾次,得到多個結果,然后投票決定
優缺點:
(1) Bagging通過降低基分類器的方差,改善了泛化誤差;(2)其性能依賴于基分類器的穩定性;如果基分類器不穩定,bagging有助于降低訓練數據的隨機波動導致的誤差;如果穩定,則集成分類器的誤差主要由基分類器的偏倚引起;(3)由于每個樣本被選中的概率相同,因此bagging并不側重于訓練數據集中的任何特定實例
1.優點,可以減小方差和減小過擬合
2.缺點,重復有放回采樣的道德樣本集改變了數據原有的分布,因此在一定程度上引入了偏差,對最終的結果預測會造成一定程度的影響
為什么說Bagging算法會減少方差?
首先我們來看看偏差和方差的概念
偏差:描述的是預測值(估計值)的期望與真實值之間的差距。偏差越大,越偏離真實數據
方差:描述的是預測值的變化范圍,離散程度,也就是離其期望值的距離。方差越大
bias描述的是根據樣本擬合出的模型的輸出預測結果的期望與樣本真實結果的差距,簡單講,就是在樣本上擬合的好不好。要想在bias上表現好,low bias,就得復雜化模型,增加模型的參數,但這樣容易過擬合 (overfitting),過擬合對應上圖是high variance,點很分散。low bias對應就是點都打在靶心附近,所以瞄的是準的,但手不一定穩。 varience描述的是樣本上訓練出來的模型在測試集上的表現,要想在variance上表現好,low varience,就要簡化模型,減少模型的參數,但這樣容易欠擬合(unfitting),欠擬合對應上圖是high bias,點偏離中心。low variance對應就是點都打的很集中,但不一定是靶心附近,手很穩,但是瞄的不準。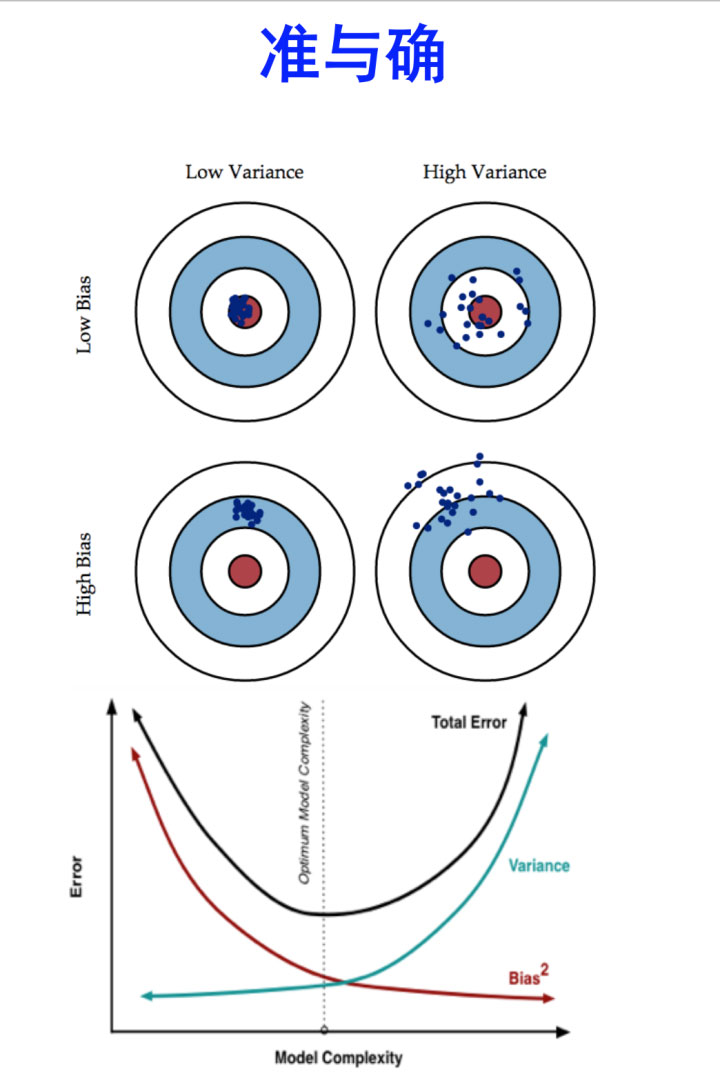
bagging是對許多強(甚至過強)的分類器求平均。在這里,每個單獨的分類器的bias都是低的,平均之后bias依然低;而每個單獨的分類器都強到可能產生overfitting的程度,也就是variance高,求平均的操作起到的作用就是降低這個variance。
boosting是把許多弱的分類器組合成一個強的分類器。弱的分類器bias高,而強的分類器bias低,所以說boosting起到了降低bias的作用。variance不是boosting的主要考慮因素。Boosting則是迭代算法,每一次迭代都根據上一次迭代的預測結果對樣本進行加權,所以隨著迭代不斷進行,誤差會越來越小,所以模型的bias會不斷降低。這種算法無法并行,例子比如Adaptive Boosting
Bagging和Rand Forest
1)Rand Forest是選與輸入樣本的數目相同多的次數(可能一個樣本會被選取多次,同時也會造成一些樣本不會被選取到),而Bagging一般選取比輸入樣本的數目少的樣本
2)bagging是用全部特征來得到分類器,而Rand Forest是需要從全部特征中選取其中的一部分來訓練得到分類器; 一般Rand forest效果比Bagging效果好!
三、Bagging用于分類我們使用葡萄酒數據集進行建模(數據處理):
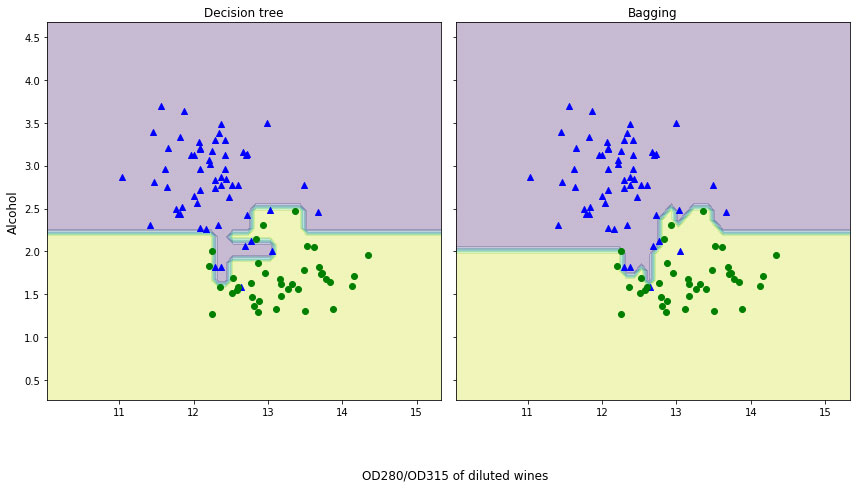
# -*- coding: utf-8 -*-'''Created on Tue Aug 11 10:12:48 2020@author: Admin'''## 我們使用葡萄酒數據集進行建模(數據處理)import pandas as pd df_wine = pd.read_csv(’https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data’,header=None)df_wine.columns = [’Class label’, ’Alcohol’,’Malic acid’, ’Ash’,’Alcalinity of ash’,’Magnesium’, ’Total phenols’, ’Flavanoids’, ’Nonflavanoid phenols’,’Proanthocyanins’,’Color intensity’, ’Hue’,’OD280/OD315 of diluted wines’,’Proline’]df_wine[’Class label’].value_counts()’’’2 711 593 48Name: Class label, dtype: int64’’’df_wine = df_wine[df_wine[’Class label’] != 1] # drop 1 classy = df_wine[’Class label’].valuesX = df_wine[[’Alcohol’,’OD280/OD315 of diluted wines’]].valuesfrom sklearn.model_selection import train_test_split # 切分訓練集與測試集from sklearn.preprocessing import LabelEncoder # 標簽化分類變量le = LabelEncoder()y = le.fit_transform(y) #吧y值改為0和1 ,原來是2和3 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) #2、8分## 我們使用單一決策樹分類:from sklearn.tree import DecisionTreeClassifiertree = DecisionTreeClassifier(criterion=’entropy’,random_state=1,max_depth=None) #選擇決策樹為基本分類器from sklearn.metrics import accuracy_score #計算準確率tree = tree.fit(X_train,y_train)y_train_pred = tree.predict(X_train)y_test_pred = tree.predict(X_test)tree_train = accuracy_score(y_train,y_train_pred) #訓練集準確率tree_test = accuracy_score(y_test,y_test_pred) #測試集準確率print(’Decision tree train/test accuracies %.3f/%.3f’ % (tree_train,tree_test))#Decision tree train/test accuracies 1.000/0.833## 我們使用BaggingClassifier分類:from sklearn.ensemble import BaggingClassifiertree = DecisionTreeClassifier(criterion=’entropy’,random_state=1,max_depth=None) #選擇決策樹為基本分類器bag = BaggingClassifier(base_estimator=tree,n_estimators=500,max_samples=1.0,max_features=1.0,bootstrap=True,bootstrap_features=False,n_jobs=1,random_state=1)from sklearn.metrics import accuracy_scorebag = bag.fit(X_train,y_train)y_train_pred = bag.predict(X_train)y_test_pred = bag.predict(X_test)bag_train = accuracy_score(y_train,y_train_pred)bag_test = accuracy_score(y_test,y_test_pred)print(’Bagging train/test accuracies %.3f/%.3f’ % (bag_train,bag_test))#Bagging train/test accuracies 1.000/0.917’’’我們可以對比兩個準確率,測試準確率較之決策樹得到了顯著的提高我們來對比下這兩個分類方法上的差異’’’## 我們來對比下這兩個分類方法上的差異x_min = X_train[:, 0].min() - 1x_max = X_train[:, 0].max() + 1y_min = X_train[:, 1].min() - 1y_max = X_train[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))f, axarr = plt.subplots(nrows=1, ncols=2,sharex=’col’,sharey=’row’,figsize=(12, 6))for idx, clf, tt in zip([0, 1],[tree, bag],[’Decision tree’, ’Bagging’]): clf.fit(X_train, y_train) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) #ravel()方法將數組維度拉成一維數組,np.c_是按行連接兩個矩陣,就是把兩矩陣左右相加,要求行數相等 Z = Z.reshape(xx.shape) axarr[idx].contourf(xx, yy, Z, alpha=0.3) axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c=’blue’, marker=’^’) axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c=’green’, marker=’o’) axarr[idx].set_title(tt)axarr[0].set_ylabel(’Alcohol’, fontsize=12)plt.tight_layout()plt.text(0, -0.2,s=’OD280/OD315 of diluted wines’,ha=’center’,va=’center’,fontsize=12,transform=axarr[1].transAxes)plt.show()’’’從結果圖看起來,三個節點深度的決策樹分段線性決策邊界在Bagging集成中看起來更加平滑’’’
class sklearn.ensemble.BaggingClassifier(base_estimator=None, n_estimators=10, max_samples=1.0, max_features=1.0, bootstrap=True, bootstrap_features=False, oob_score=False, warm_start=False, n_jobs=None, random_state=None, verbose=0)
參數說明:
base_estimator:Object or None。None代表默認是DecisionTree,Object可以指定基估計器(base estimator) n_estimators:int, optional (default=10) 。 要集成的基估計器的個數 max_samples: int or float, optional (default=1.0)。決定從x_train抽取去訓練基估計器的樣本數量。int 代表抽取數量,float代表抽取比例 max_features : int or float, optional (default=1.0)。決定從x_train抽取去訓練基估計器的特征數量。int 代表抽取數量,float代表抽取比例 bootstrap : boolean, optional (default=True) 決定樣本子集的抽樣方式(有放回和不放回) bootstrap_features : boolean, optional (default=False)決定特征子集的抽樣方式(有放回和不放回) oob_score : bool 決定是否使用包外估計(out of bag estimate)泛化誤差 warm_start : bool, optional (default=False) 設置為True時,請重用上一個調用的解決方案以適合并為集合添加更多估計量,否則,僅適合一個全新的集合 n_jobs : int, optional (default=None) fit和 并行運行的作業數predict。None除非joblib.parallel_backend上下文中,否則表示1 。-1表示使用所有處理器 random_state : int, RandomState instance or None, optional (default=None)。如果int,random_state是隨機數生成器使用的種子; 如果RandomState的實例,random_state是隨機數生成器; 如果None,則隨機數生成器是由np.random使用的RandomState實例 verbose : int, optional (default=0)屬性介紹:
estimators_ : list of estimators。The collection of fitted sub-estimators. estimators_samples_ : list of arrays estimators_features_ : list of arrays oob_score_ : float,使用包外估計這個訓練數據集的得分。 oob_prediction_ : array of shape = [n_samples]。在訓練集上用out-of-bag估計計算的預測。 如果n_estimator很小,則可能在抽樣過程中數據點不會被忽略。 在這種情況下,oob_prediction_可能包含NaN。四、Bagging用于回歸再補充一下Bagging用于回歸
# -*- coding: utf-8 -*-'''Created on Tue Aug 11 10:12:48 2020@author: Admin'''# 從 sklearn.datasets 導入波士頓房價數據讀取器。from sklearn.datasets import load_boston# 從讀取房價數據存儲在變量 boston 中。boston = load_boston()# 從sklearn.cross_validation 導入數據分割器。from sklearn.model_selection import train_test_splitX = boston.datay = boston.target# 隨機采樣 25% 的數據構建測試樣本,其余作為訓練樣本。X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=33,test_size=0.25)# 從 sklearn.preprocessing 導入數據標準化模塊。from sklearn.preprocessing import StandardScaler# 分別初始化對特征和目標值的標準化器。ss_X = StandardScaler()ss_y = StandardScaler()# 分別對訓練和測試數據的特征以及目標值進行標準化處理。X_train = ss_X.fit_transform(X_train)X_test = ss_X.transform(X_test)y_train = ss_y.fit_transform(y_train.reshape(-1,1))y_test = ss_y.transform(y_test.reshape(-1,1))#BaggingRegressorfrom sklearn.ensemble import BaggingRegressorbagr = BaggingRegressor(n_estimators=500,max_samples=1.0,max_features=1.0,bootstrap=True,bootstrap_features=False,n_jobs=1,random_state=1)bagr.fit(X_train, y_train)bagr_y_predict = bagr.predict(X_test)from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error# 使用 R-squared、MSE 以及 MAE 指標對默認配置的隨機回歸森林在測試集上進行性能評估。print(’R-squared value of BaggingRegressor:’, bagr.score(X_test, y_test))print(’The mean squared error of BaggingRegressor:’, mean_squared_error( ss_y.inverse_transform(y_test), ss_y.inverse_transform(bagr_y_predict)))print(’The mean absoluate error of BaggingRegressor:’, mean_absolute_error( ss_y.inverse_transform(y_test), ss_y.inverse_transform(bagr_y_predict)))’’’R-squared value of BaggingRegressor: 0.8417369323817341The mean squared error of BaggingRegressor: 12.27192314456692The mean absoluate error of BaggingRegressor: 2.2523244094488195’’’#隨機森林實現from sklearn.ensemble import RandomForestRegressorrfr = RandomForestRegressor(random_state=1)rfr.fit(X_train, y_train)rfr_y_predict = rfr.predict(X_test)# 使用 R-squared、MSE 以及 MAE 指標對默認配置的隨機回歸森林在測試集上進行性能評估。print(’R-squared value of RandomForestRegressor:’, rfr.score(X_test, y_test))print(’The mean squared error of RandomForestRegressor:’, mean_squared_error( ss_y.inverse_transform(y_test), ss_y.inverse_transform(rfr_y_predict)))print(’The mean absoluate error of RandomForestRegressor:’, mean_absolute_error( ss_y.inverse_transform(y_test), ss_y.inverse_transform(rfr_y_predict)))’’’R-squared value of RandomForestRegressor: 0.8083674472512408The mean squared error of RandomForestRegressor: 14.859436220472439The mean absoluate error of RandomForestRegressor: 2.4732283464566924’’’#用Bagging集成隨機森林bagr = BaggingRegressor(base_estimator=rfr,n_estimators=500,max_samples=1.0,max_features=1.0,bootstrap=True,bootstrap_features=False,n_jobs=1,random_state=1)bagr.fit(X_train, y_train)bagr_y_predict = bagr.predict(X_test)# 使用 R-squared、MSE 以及 MAE 指標對默認配置的隨機回歸森林在測試集上進行性能評估。print(’R-squared value of BaggingRegressor:’, bagr.score(X_test, y_test))print(’The mean squared error of BaggingRegressor:’, mean_squared_error( ss_y.inverse_transform(y_test), ss_y.inverse_transform(bagr_y_predict)))print(’The mean absoluate error of BaggingRegressor:’, mean_absolute_error( ss_y.inverse_transform(y_test), ss_y.inverse_transform(bagr_y_predict)))’’’R-squared value of BaggingRegressor: 0.8226953069216255The mean squared error of BaggingRegressor: 13.748435433319694The mean absoluate error of BaggingRegressor: 2.3744811023622048’’’
以上就是詳解Bagging算法的原理及Python實現的詳細內容,更多關于Python Bagging算法 的資料請關注好吧啦網其它相關文章!
相關文章:
 網公網安備
網公網安備