Python爬蟲基礎(chǔ)之簡單說一下scrapy的框架結(jié)構(gòu)
思考
scrapy 為什么是框架而不是庫? scrapy是如何工作的?項目結(jié)構(gòu)在開始爬取之前,必須創(chuàng)建一個新的Scrapy項目。進入您打算存儲代碼的目錄中,運行下列命令:
注意:創(chuàng)建項目時,會在當前目錄下新建爬蟲項目的目錄。
這些文件分別是:
scrapy.cfg:項目的配置文件 quotes/:該項目的python模塊。之后您將在此加入代碼 quotes/items.py:項目中的item文件 quotes/middlewares.py:爬蟲中間件、下載中間件(處理請求體與響應體) quotes/pipelines.py:項目中的pipelines文件 quotes/settings.py:項目的設(shè)置文件 quotes/spiders/:放置spider代碼的目錄Scrapy原理圖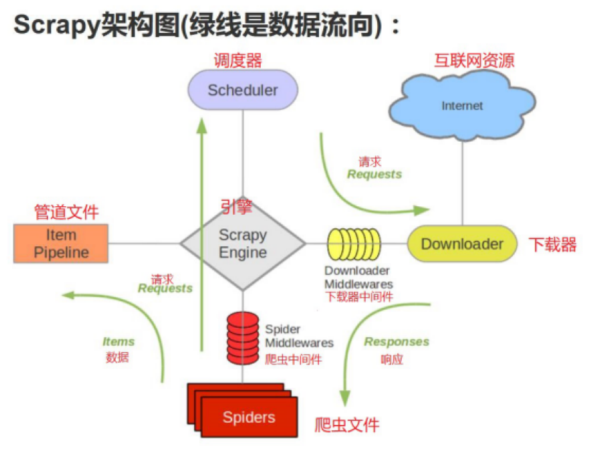
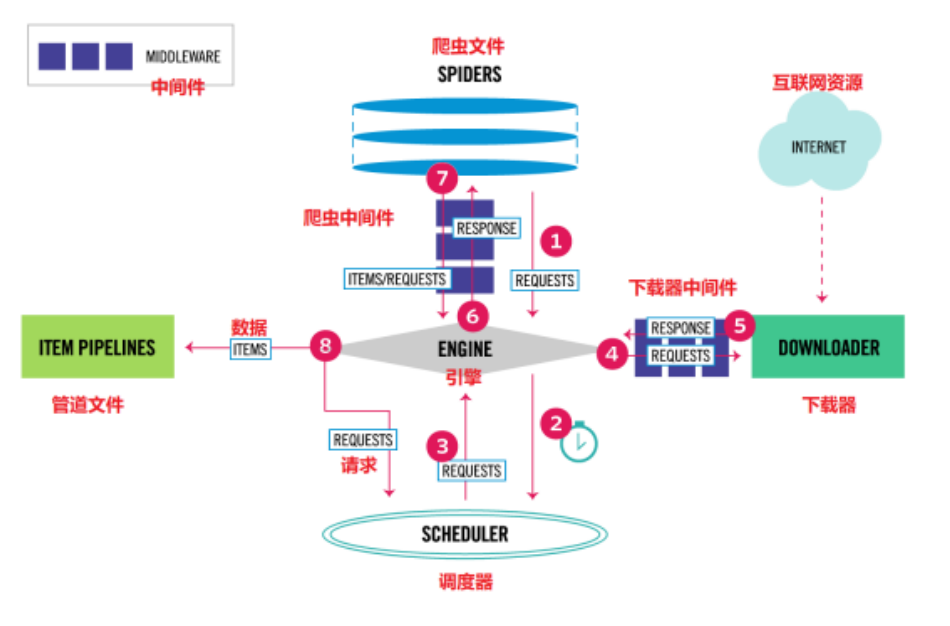
1.Engine。引擎,處理整個系統(tǒng)的數(shù)據(jù)流處理、觸發(fā)事務,是整個框架的核心。
2.ltem。項目,它定義了爬取結(jié)果的數(shù)據(jù)結(jié)構(gòu),爬取的數(shù)據(jù)會被賦值成該ltem對象。
3.Scheduler。調(diào)度器,接受引擎發(fā)過來的請求并將其加入隊列中,在引擎再次請求的時候?qū)⒄埱筇峁┙o引擎。
4.Downloader。下載器,下載網(wǎng)頁內(nèi)容,并將網(wǎng)頁內(nèi)容返回給蜘蛛。
5.Spiders。蜘蛛,其內(nèi)定義了爬取的邏輯和網(wǎng)頁的解析規(guī)則,它主要負責解析響應并生成提結(jié)果和新的請求。
6.Item Pipeline。項目管道,負責處理由蜘蛛從網(wǎng)頁中抽取的項目,它的主要任務是清洗、驗證和存儲數(shù)據(jù)。
7.Downloader Middlewares。下載器中間件,位于引擎和下載器之間的鉤子框架,主要處理引擎與下載器之間的請求及響應。
8.Spider Middlewares。蜘蛛中間件,位于引擎和蜘蛛之間的鉤子框架,主要處理蜘蛛輸入的響應和輸出的結(jié)果及新的請求。
到此這篇關(guān)于Python爬蟲基礎(chǔ)之簡單說一下scrapy的框架結(jié)構(gòu)的文章就介紹到這了,更多相關(guān)scrapy的框架結(jié)構(gòu)內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. PHP使用Swagger生成好看的API文檔2. ASP.NET MVC使用jQuery ui的progressbar實現(xiàn)進度條3. Python3 json模塊之編碼解碼方法講解4. Python 制作查詢商品歷史價格的小工具5. Python 如何調(diào)試程序崩潰錯誤6. Python 利用Entrez庫篩選下載PubMed文獻摘要的示例7. ASP基礎(chǔ)知識VBScript基本元素講解8. python使用jenkins發(fā)送企業(yè)微信通知的實現(xiàn)9. Python sublime安裝及配置過程詳解10. Python 合并拼接字符串的方法
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備