淺談Django QuerySet對象(模型.objects)的常用方法
準備工作:
新建一個項目,在項目中新家一個app,名字自取。將app添加值settings.py中,然后配置settings連接數據庫。
在app中的models中新建模型:
from django.db import models# Create your models here.class Author(models.Model): '''作者模型''' name = models.CharField(max_length=100) age = models.IntegerField() email = models.EmailField() class Meta: db_table = ’author’class Publisher(models.Model): '''出版社模型''' name = models.CharField(max_length=300) class Meta: db_table = ’publisher’class Book(models.Model): '''圖書模型''' name = models.CharField(max_length=300) pages = models.IntegerField() price = models.FloatField() #書的定價 rating = models.FloatField() author = models.ForeignKey(Author, on_delete=models.CASCADE) publisher = models.ForeignKey(Publisher, on_delete=models.CASCADE) class Meta: db_table = ’book’class BookOrder(models.Model): '''圖書訂單模型''' book = models.ForeignKey('Book', on_delete=models.CASCADE) price = models.FloatField() #書賣出去的真正價格 class Meta: db_table = ’book_order’
執行makemigrations后在migrate。
然后手動向表中添加數據,例如我添加的信息:
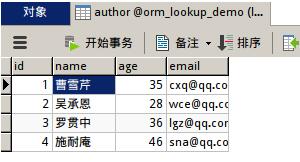
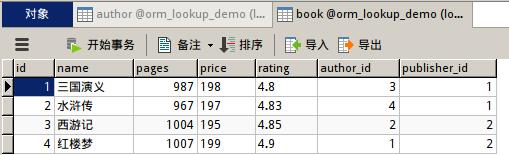
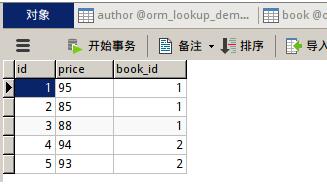
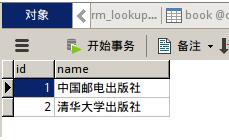
然后配置urls,直至項目運行成功。
1.filter:
過濾,將滿足條件的數據提取出來,返回一個新的QuerySet。
2. exclude:
排除,排除滿足條件的數據,返回一個新的QuerySet。
例如,取出book中id大于等于2的圖書,并且id不能等于3的圖書。示例代碼:
books = models.Book.objects.filter(id__gt=1).exclude(id=3)
我們也可以使用Q表達式來實現,
from django.db.models import Qbooks = models.Book.objects.filter(id__gt=1).filter(~Q(id=3))
3. annotate:
給QuerySet中的每個對象都添加一個使用查詢表達式(聚合函數、F表達式、Q表達式、Func表達式等)的新字段。
例如 給每本圖書都添加一個字段叫author_name
from django.db.models import Fbooks = models.Book.objects.annotate(author_name = F(’author__name’))
注意:
Book模型下面最開始是沒有author_name這個屬性的。只有一個author屬性連接的一個外鍵.
author__name是book下的author屬性下的name,即book這個表通過外鍵訪問到author這個表中的name值。
執行完上述代碼之后就在book中創建了一個新的屬性author_name,但是只在內存中,不會映射到數據庫中去。
4.order_by:
指定將查詢的結果根據某個字段進行排序。如果要倒敘排序,那么可以在這個字段的前面加一個負號。
示例
def index2(request): # 1. 將book中的price屬性按照從小到大進行排序 # books = models.Book.objects.order_by(’price’) # for book in books: # print('%s-%s'%(book.name,book.price)) # 2. 將book中的price屬性按照從大到小進行排序 books = models.Book.objects.order_by(’-price’) for book in books: print('%s-%s'%(book.name,book.price)) return HttpResponse(’success’)
修改對應注釋代碼哪呢個查看到效果。
需求:對價格進行排序,價格一樣的就按照頁數來進行排序,價格從小到大,頁數從大到小。為了方便查看效果,可以先去數據庫中修改數據。
def index2(request): # 1. 將book中的price屬性按照從小到大進行排序 # books = models.Book.objects.order_by(’price’) # for book in books: # print('%s-%s'%(book.name,book.price)) # 2. 將book中的price屬性按照從大到小進行排序 # books = models.Book.objects.order_by(’-price’) # for book in books: # print('%s-%s'%(book.name,book.price)) # 3. 對價格進行排序,價格一樣的就按照頁數來進行排序,價格從小到大,頁數從大到小。 books = models.Book.objects.order_by(’price’,’-pages’) for book in books: print('%s-%s-%s'%(book.name,book.price,book.pages)) return HttpResponse(’success’)
注意:
books = models.Book.objects.order_by(’price’,’-pages’)不等于books = models.Book.objects.order_by(’price’).order_by(’-pages’)
如果使用多個order_by,會把前面排序的規則給打亂,只會使用最后面的一個排序方式。
order_by方法并沒有改變數據庫中的信息位置,只是我們將數據取出來進行了排序。
那么如果我們對數據庫中的信息進行了排序,這樣我們就不用每次取數據都需要進行一次排序了。應該怎樣做呢?
我們只需要在模型中添加點代碼就可以了。
例如:我們在Book者惡搞模型中對價格進行排序,價格一樣的就按照頁數來進行排序,價格從小到大,頁數從大到小。
修改Book中的class Meta中的代碼:
class Meta: db_table = ’book_order’ ordering = [’price’,’-pages’]
這樣就對數據庫中的信息進行了排序,我們在去數據 的時候也不用使用order_by來進行排序了。但是這樣需要重新makegrations和migrate一下,這里就不做演示了。
需求:根據每本圖書的銷量來進行排序
from django.db.models import Q,F,Count
def index2(request):
# 1. 將book中的price屬性按照從小到大進行排序 # books = models.Book.objects.order_by(’price’) # for book in books: # print('%s-%s'%(book.name,book.price)) # 2. 將book中的price屬性按照從大到小進行排序 # books = models.Book.objects.order_by(’-price’) # for book in books: # print('%s-%s'%(book.name,book.price)) # 3. 對價格進行排序,價格一樣的就按照頁數來進行排序,價格從小到大,頁數從大到小。 # books = models.Book.objects.order_by(’price’,’-pages’) # for book in books: # print('%s-%s-%s'%(book.name,book.price,book.pages)) # 4. 根據每本圖書的銷量來進行排序 results = models.Book.objects.annotate(sale_num=Count(’bookorder__id’)).order_by(’sale_num’) for result in results: print('%s-%s'%(result.name,result.sale_num)) return HttpResponse(’success’)
因為Book這個模型中沒有sale_num這個屬性,所以我們需要使用annotate這個方法來創建一個sale_num屬性,然后使用Count方法進行賦值,然后使用order_by 進行排序。就實現了這個需求。
5. values:
用來指定在提取數據出來,需要提取哪些字段。默認情況下會把表中所有的字段全部都提取出來,可以使用values來進行指定,并且使用了values方法后,提取出的QuerySet中的數據類型不是模型,而是在values方法中指定的字段和值形成的字典。
需求: 只需要提取Book中的id 和 name
示例:
def index3(request):
# 1. 只需要提取Book中的id 和 name books = models.Book.objects.values(’id’,’name’) for book in books: print(book) return HttpResponse(’success’)
注意: 返回的是一個字典類型。字典的key就是屬性名,value是屬性值。
需求:提取Book中的name和author__name,并且字典中的key自己指定,不使用默認的。字典的key分別為bookName和authorNmae
def index3(request):
# 1. 只需要提取Book中的id 和 name # books = models.Book.objects.values(’id’,’name’) # for book in books: # print(book) # 需求:提取Book中的name和author__name,并且字典中的key自己指定,不使用默認的。 # 字典的key分別為`bookName`和`authorNmae` books = models.Book.objects.values(bookName=F(’name’),authorName=F(’author__name’)) for book in books: print(book) return HttpResponse(’success’)
注意:
自己取名字不能取該模型的屬性名,否則會報錯。
如果在value中不傳遞任何參數,那么會獲取這個模型所有的值。返回的還是一個字典。
6:values_list:
類似于values。只不過返回的QuerySet中,存儲的不是字典,而是元組。操作和values是一樣的,只是返回類型不一樣。
注意: 當我們使用此方法只返回一個值的時候,那么這個元祖中只有一個值,我們可以添加一個參數flat=True,將元祖去掉,從而得到一個字符竄。只有當values_list中只有一個值的時候才能使用這個方法:
示例:
books = models.Book.objects.values_list(’name’,flat=True)
7. all:
獲取這個ORM模型的QuerySet對象。即獲取所有的數據。
獲取Book中所有數據
示例:
books = models.Book.objects.all()
8.select_related:
在提取某個模型的數據的同時,也提前將相關聯的數據提取出來。比如提取文章數據,可以使用select_related將author信息提取出來,以后再次使用article.author的時候就不需要再次去訪問數據庫了。可以減少數據庫查詢的次數。
def index4(request): books = models.Book.objects.select_related(’author’) for book in books: print(book.author.name) return HttpResponse(’succrss’)
注意: select_related只能使用在設置了外鍵的模型中(即只能在一對多模型上,不能多對一,多對多等),比如我們只在Book設置了author外鍵和publisher外鍵。那么select_related里面只能傳如這兩個參數,而不能傳入別的參數,如BookOrder,因為我們是在BookOrder中設置的外鍵連接到Book,并沒有在Book中設置外鍵連接到BookOrder這個模型。
9. prefetch_related:
這個方法和select_related非常的類似,就是在訪問多個表中的數據的時候,減少查詢的次數。這個方法是為了解決多對一和多對多的關系的查詢問題。
需求:從book中通過prefetch_related查詢BookOrder中的信息。
示例代碼
def index5(request): books = models.Book.objects.prefetch_related('bookorder_set') for book in books: print(’*’*30) print(book.name) orders = book.bookorder_set.all() for order in orders: print(order.id) return HttpResponse(’success’)
prefetch_related方法也能辦到select_related方法能辦到的事情,只是select_related方法效率比prefetch_related方法效率高一點。所以能使用select_related方法的話就是用這個方法。但是這兩種方法的執行效率都比傳統的方法執行效率高。傳統的方法就是先返回book對象,再通過book去查詢對應的外鍵的相關信息。
10. defer:
在一些表中,可能存在很多的字段,但是一些字段的數據量可能是比較龐大的,而此時你又不需要,比如我們在獲取文章列表的時候,文章的內容我們是不需要的,因此這時候我們就可以使用defer來過濾掉一些字段。這個字段跟values有點類似,只不過defer返回的不是字典,而是模型。
需求:過濾掉book 的name字段
def index6(request): # 過濾掉book的name字段 books = models.Book.objects.defer(’name’) for book in books: print(book.id) return HttpResponse(’sucdess’)
注意: 我們在使用defer過濾掉name字段之后,我們還是可以訪問到name屬性,是因為當我們訪問name屬性的時候,Django又去執行了一遍sql語句查詢的代碼。所以在我們開發的過程中,除非我們確定不會使用到此屬性,否則不要去過濾它。
defer雖然能過濾字段,但是有些字段是不能過濾的,比如id,即使你過濾了,也會提取出來。
11. only:
跟defer類似,只不過defer是過濾掉指定的字段,而only是只提取指定的字段。
需求:只提取name屬性
# 只提取name屬性 books = models.Book.objects.only(’name’) for book in books: print(book.id,book.name)
注意: id這個字段我們是不能操作的,像上面一樣,我們沒有提取id屬性,但是還是給我們提取出來了。所以id屬性是一定會被提取出來的。
和defer一樣,就算我們沒有提取某個屬性出來,我們還是可以訪問到的,只是會重新執行一遍sql代碼而已。
12. get:
獲取滿足條件的數據。這個函數只能返回一條數據,并且如果給的條件有多條數據,那么這個方法會拋出MultipleObjectsReturned錯誤,如果給的條件沒有任何數據,那么就會拋出DoesNotExit錯誤。所以這個方法在獲取數據的只能,只能有且只有一條。
# 獲取id為1的數據book = models.Book.objects.get(id=1)
13. create:
創建一條數據,并且保存到數據庫中。這個方法相當于先用指定的模型創建一個對象,然后再調用這個對象的save方法。
publusher = models.Publisher.objects.create(name=’知了出版社’)
14. get_or_create:
根據某個條件進行查找,如果找到了那么就返回這條數據,如果沒有查找到,那么就創建一個。
result = models.Publisher.objects.get_or_create(name=’知了出版社’)print(result)
會返回一個元祖
查找的對象以及是否創建了這條數據。False就是沒有創建這條數據。
15. bulk_create:
和create方法類似,只是這個方法可以一次性創建多個數據。
publusher = models.Publisher.objects.bulk_create([models.Publisher(name=’123出版社’),models.Publisher(name=’abc出版社’),])
16. count:
獲取提取的數據的個數。如果想要知道總共有多少條數據,那么建議使用count,而不是使用len(articles)這種。因為count在底層是使用select count(*)來實現的,這種方式比使用len函數更加的高效。
count = models.Book.objects.filter(name=’xxx’).count()
17. first和last:
返回QuerySet中的第一條和最后一條數據。如果為空則返回none。
18. aggregate:
使用聚合函數。
19. exists:
判斷某個條件的數據是否存在。如果要判斷某個條件的元素是否存在,那么建議使用exists,這比使用count或者直接判斷QuerySet更有效得多。
示例代碼如下:
# 最高效的判斷值是否存在的方法if Article.objects.filter(name=’三國演義’).exists(): print(True)# 比上面的方法效率低一點if Article.objects.filter(name=’三國演義’).count() > 0: print(True)# 還要比上面的效率低if Article.objects.filter(name=’三國演義’): print(True)
20. distinct:
去除掉那些重復的數據。這個方法如果底層數據庫用的是MySQL,那么不能傳遞任何的參數。
需求:提取所有銷售的價格超過80元的圖書,并且刪掉那些重復的,那么可以使用distinct來幫我們實現,示例代碼如下:
books = models.Book.objects.filter(bookorder__price__gte=80).distinct() for book in books: print(book.name)
并且distinct只會剔除那些完全相同的數據,如果有一個字段不相同,都不會剔除的。
如果在distinct之前使用了order_by,那么因為order_by會提取order_by中指定的字段,因此再使用distinct就會根據多個字段來進行唯一化,所以就不會把那些重復的數據刪掉。
示例:
orders = models.BookOrder.objects.order_by('pages').values('book_id').distinct()
21. update:
執行更新操作,在SQL底層走的也是update命令。比如要將所有圖書的價格都提高10元。
book = models.Book.objects.update(price=F(’price’)+5)
22. delete:
刪除所有滿足條件的數據。刪除數據的時候,要注意on_delete指定的處理方式。
例如刪除作者id大于等于3的數據
result = models.Author.objects.get(id__gte=4).delete()
刪除數據時一定要對你的表了如指掌,因為可能會牽連到很多其他數據。像在這個地方將這個作者刪除了之后,那么這個作者對應的圖書也將會被刪除。
23. 切片操作:
有時候我們查找數據,有可能只需要其中的一部分。那么這時候可以使用切片操作來幫我們完成。QuerySet使用切片操作就跟列表使用切片操作是一樣的。
# 獲取1,2兩條數據 books = models.Book.objects.all()[1:3] for book in books: print(book)
以上這篇淺談Django QuerySet對象(模型.objects)的常用方法就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持好吧啦網。
相關文章:
 網公網安備
網公網安備