python爬蟲使用正則爬取網站的實現
本文章的所有代碼和相關文章, 僅用于經驗技術交流分享,禁止將相關技術應用到不正當途徑,濫用技術產生的風險與本人無關。
本文章是自己學習的一些記錄。歡迎各位大佬點評!
首先
今天是第一天寫博客,感受到了博客的魅力,博客不僅能夠記錄每天的代碼學習情況,并且可以當作是自己的學習筆記,以便在后面知識點不清楚的時候前來復習。這是第一次使用爬蟲爬取網頁,這里展示的是爬取豆瓣電影top250的整個過程,歡迎大家指點。
這里我只爬取了電影鏈接和電影名稱,如果想要更加完整的爬取代碼,請聯系我。qq 1540741344 歡迎交流
開發工具: pycharm、chrome
分析網頁
在開發之前你首先要去你所要爬取的網頁提取出你要爬取的網頁鏈接,并且將網頁分析出你想要的內容。
在開發之前首先要導入幾個模塊,模塊描述如下,具體不知道怎么導入包的可以看我下一篇內容
首先定義幾個函數,便于將各個步驟的工作分開便于代碼管理,我這里是分成了7個函數,分別如下:
@主函數入口
if __name__=='__main__': #程序執行入口 main()
@捕獲網頁html內容 askURL(url)
這里的head的提取是在chrome中分析網頁源碼獲得的,具體我也不做過多解釋,大家可以百度
def askURL(url): #得到指定網頁信息的內容 #爬取一個網頁的數據 # 用戶代理,本質上是告訴服務器,我們是以什么樣的機器來訪問網站,以便接受什么樣的水平數據 head={'User-Agent':'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 84.0.4147.89 Safari / 537.36'} request=urllib.request.Request(url,headers=head) #request對象接受封裝的信息,通過urllib攜帶headers訪問信息訪問url response=urllib.request.urlopen(request) #用于接收返回的網頁信息 html=response.read().decode('utf-8') #通過read方法讀取response對象里的網頁信息,使用“utf-8” return html
@將baseurl里的內容進行逐一解析 getData(baseURL)這里面的findlink和findname是正則表達式,可以首先定義全局變量
findlink=r’<a class='' href='http://m.b3g6.com/bcjs/(.*?)'’findname=r’<span class='title'>(.*?)</span>’
def getData(baseURL): dataList=[] #初始化datalist用于存儲獲取到的數據 for i in range(0,10): url=baseURL+str(i*25) html=askURL(url) #保存獲取到的源碼 soup=BeautifulSoup(html,'html.parser') #對html進行逐一解析,使用html.parser解析器進行解析 for item in soup.find_all('div',class_='item'): #查找符合要求的字符串 ,形成列表,find_all是查找所有的class是item的div data=[] #初始化data,用于捕獲一次爬取一個div里面的內容 item=str(item) #將item數據類型轉化為字符串類型 # print(item) link=re.findall(findlink,item)[0]#使用re里的findall方法根據正則提取item里面的電影鏈接 data.append(link)#將網頁鏈接追加到data里 name=re.findall(findname,item)[0]#使用re里的findall方法根據正則提取item里面的電影名字 data.append(name)#將電影名字鏈接追加到data里 # print(link) # print(name) dataList.append(data) #將捕獲的電影鏈接和電影名存到datalist里面 return dataList #返回一個列表,里面存放的是每個電影的信息 print(dataList)
@保存捕獲的數據到excel saveData(dataList,savepath)
def saveData(dataList,savepath): #保存捕獲的內容到excel里,datalist是捕獲的數據列表,savepath是保存路徑 book=xlwt.Workbook(encoding='utf-8',style_compression=0)#初始化book對象,這里首先要導入xlwt的包 sheet=book.add_sheet('test',cell_overwrite_ok=True) #創建工作表 col=['電影詳情鏈接','電影名稱'] #列名 for i in range(0,2): sheet.write(0,i,col[i]) #將列名逐一寫入到excel for i in range(0,250): data=dataList[i] #依次將datalist里的數據獲取 for j in range(0,2): sheet.write(i+1,j,data[j]) #將data里面的數據逐一寫入 book.save(savepath)
@保存捕獲的數據到數據庫
def saveDataDb(dataList,dbpath): initDb(dbpath) #用一個函數初始化數據庫 conn=sqlite3.connect(dbpath) #初始化數據庫 cur=conn.cursor() #獲取游標 for data in dataList: for index in range(len(data)): data[index]=’'’+data[index]+’' ’#將每條數據都加上'' #每條數據之間用,隔開,定義sql語句的格式 sql=’’’ insert into test(link,name) values (%s) ’’’%’,’.join (data) cur.execute(sql) #執行sql語句 conn.commit() #提交數據庫操作 conn.close() print('爬取存入數據庫成功!')
@初始化數據庫 initDb(dbpath)
def initDb(dbpath): conn=sqlite3.connect(dbpath) cur=conn.cursor() sql=’’’ create table test( id integer primary key autoincrement, link text, name varchar ) ’’’ cur.execute(sql) conn.commit() cur.close() conn.close()
@main函數,用于調用其他函數 main()
def main(): dbpath='testSpider.db' #用于指定數據庫存儲路徑 savepath='testSpider.xls' #用于指定excel存儲路徑 baseURL='https://movie.douban.com/top250?start=' #爬取的網頁初始鏈接 dataList=getData(baseURL) saveData(dataList,savepath) saveDataDb(dataList,dbpath)
點擊運行就可以看到在左側已經生成了excel和DB文件
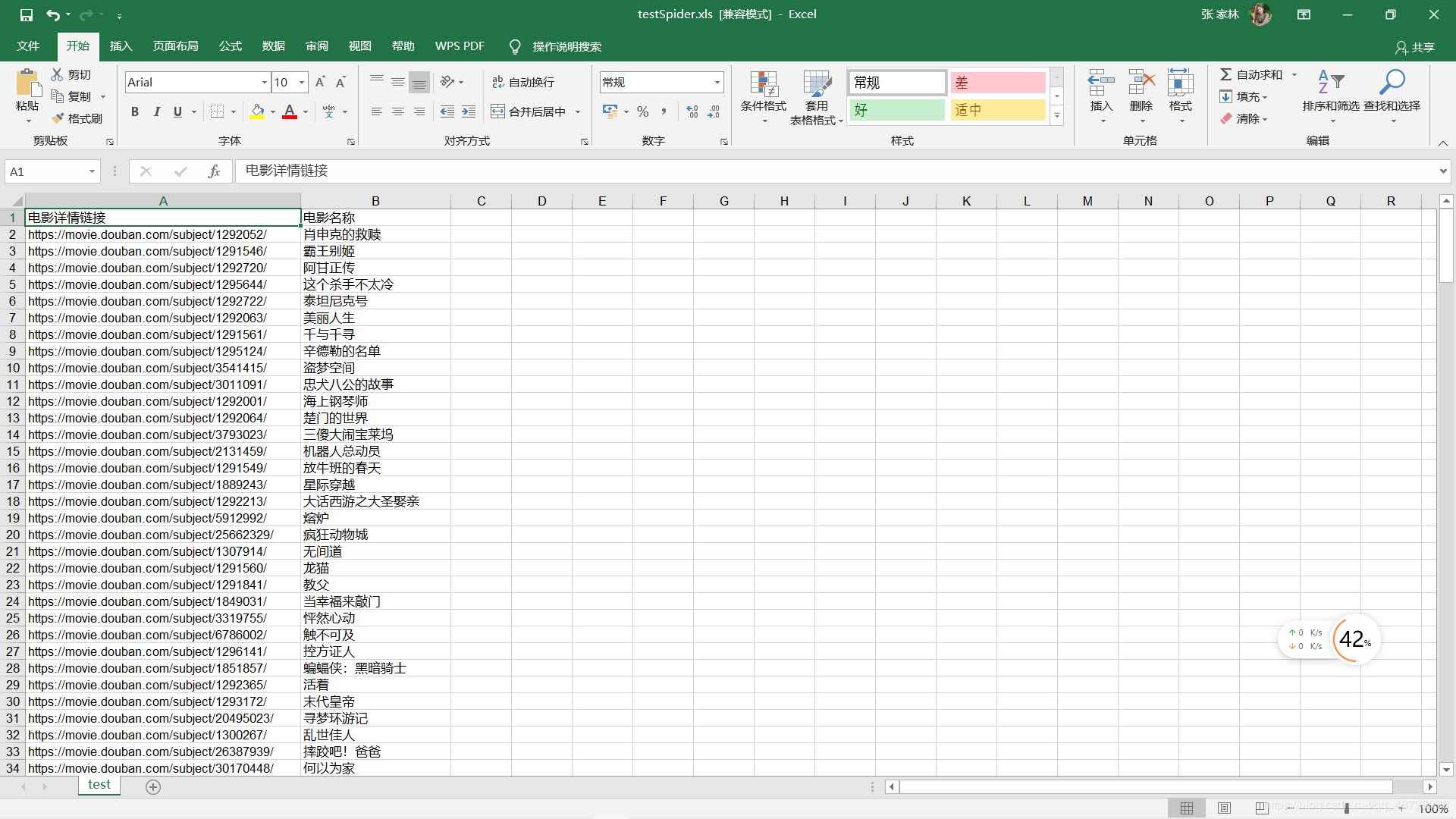
excel可以直接打開
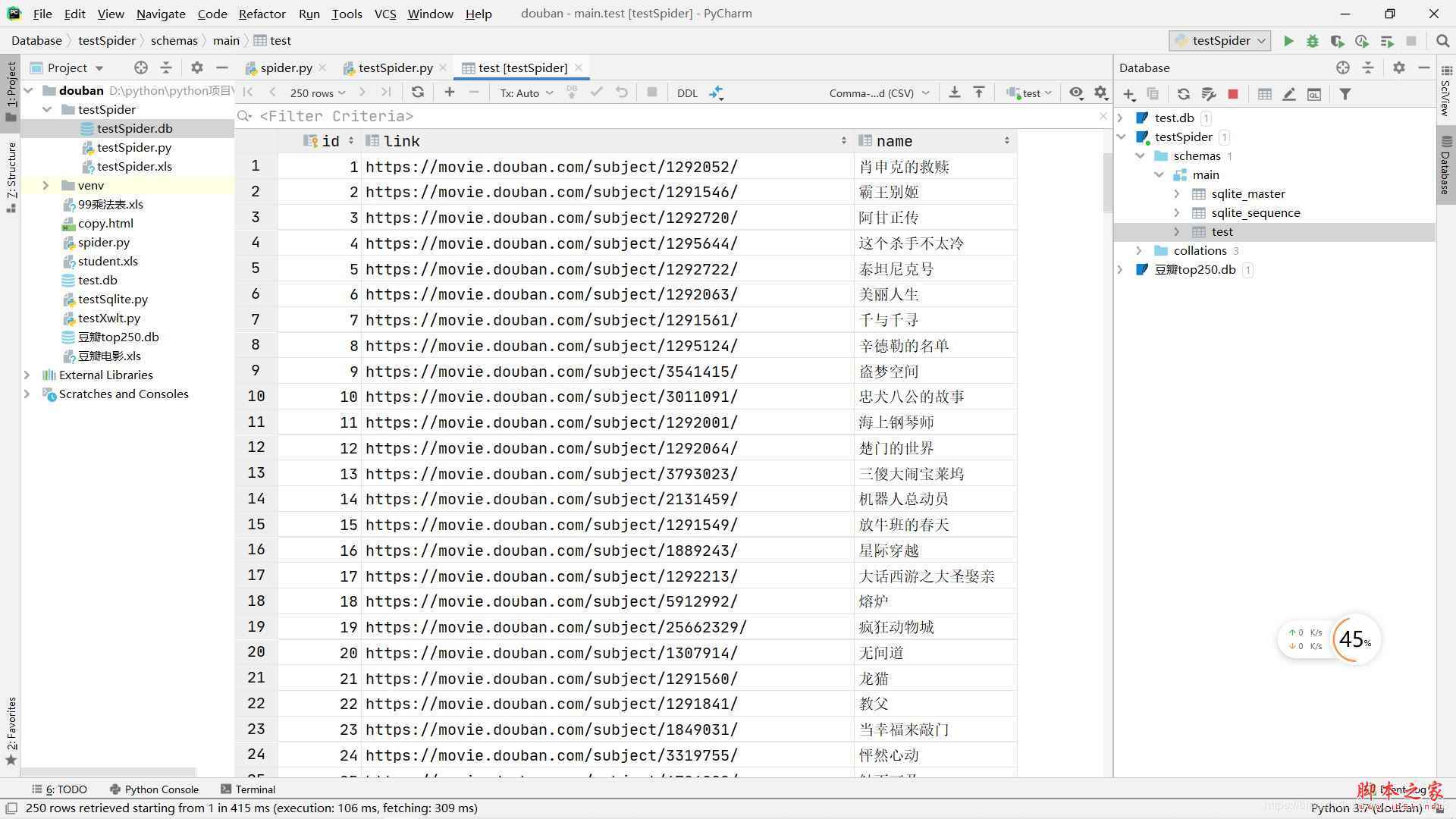
DB文件雙擊之后會在右邊打開
到這里爬蟲的基本內容就已經結束了,如果有什么不懂或者想交流的地方可以加我qq 1540741344
以下附上整個代碼
import re #網頁解析,獲取數據from bs4 import BeautifulSoup#正則表達式,進行文字匹配import urllib.request,urllib.error #制定URL,獲取網頁數據import xlwtimport sqlite3findlink=r’<a class='' href='http://m.b3g6.com/bcjs/(.*?)'’findname=r’<span class='title'>(.*?)</span>’def main(): dbpath='testSpider.db' #用于指定數據庫存儲路徑 savepath='testSpider.xls' #用于指定excel存儲路徑 baseURL='https://movie.douban.com/top250?start=' #爬取的網頁初始鏈接 dataList=getData(baseURL) saveData(dataList,savepath) saveDataDb(dataList,dbpath)def askURL(url): #得到指定網頁信息的內容 #爬取一個網頁的數據 # 用戶代理,本質上是告訴服務器,我們是以什么樣的機器來訪問網站,以便接受什么樣的水平數據 head={'User-Agent':'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 84.0.4147.89 Safari / 537.36'} request=urllib.request.Request(url,headers=head) #request對象接受封裝的信息,通過urllib攜帶headers訪問信息訪問url response=urllib.request.urlopen(request) #用于接收返回的網頁信息 html=response.read().decode('utf-8') #通過read方法讀取response對象里的網頁信息,使用“utf-8” return html #返回捕獲的網頁內容,此時還是未處理過的def getData(baseURL): dataList=[] #初始化datalist用于存儲獲取到的數據 for i in range(0,10): url=baseURL+str(i*25) html=askURL(url) #保存獲取到的源碼 soup=BeautifulSoup(html,'html.parser') #對html進行逐一解析,使用html.parser解析器進行解析 for item in soup.find_all('div',class_='item'): #查找符合要求的字符串 ,形成列表,find_all是查找所有的class是item的div data=[] #初始化data,用于捕獲一次爬取一個div里面的內容 item=str(item) #將item數據類型轉化為字符串類型 # print(item) link=re.findall(findlink,item)[0]#使用re里的findall方法根據正則提取item里面的電影鏈接 data.append(link)#將網頁鏈接追加到data里 name=re.findall(findname,item)[0]#使用re里的findall方法根據正則提取item里面的電影名字 data.append(name)#將電影名字鏈接追加到data里 # print(link) # print(name) dataList.append(data) #將捕獲的電影鏈接和電影名存到datalist里面 return dataList #返回一個列表,里面存放的是每個電影的信息 print(dataList)def saveData(dataList,savepath): #保存捕獲的內容到excel里,datalist是捕獲的數據列表,savepath是保存路徑 book=xlwt.Workbook(encoding='utf-8',style_compression=0)#初始化book對象,這里首先要導入xlwt的包 sheet=book.add_sheet('test',cell_overwrite_ok=True) #創建工作表 col=['電影詳情鏈接','電影名稱'] #列名 for i in range(0,2): sheet.write(0,i,col[i]) #將列名逐一寫入到excel for i in range(0,250): data=dataList[i] #依次將datalist里的數據獲取 for j in range(0,2): sheet.write(i+1,j,data[j]) #將data里面的數據逐一寫入 book.save(savepath) #保存excel文件def saveDataDb(dataList,dbpath): initDb(dbpath) #用一個函數初始化數據庫 conn=sqlite3.connect(dbpath) #初始化數據庫 cur=conn.cursor() #獲取游標 for data in dataList: for index in range(len(data)): data[index]=’'’+data[index]+’' ’#將每條數據都加上'' #每條數據之間用,隔開,定義sql語句的格式 sql=’’’ insert into test(link,name) values (%s) ’’’%’,’.join (data) cur.execute(sql) #執行sql語句 conn.commit() #提交數據庫操作 conn.close() print('爬取存入數據庫成功!')def initDb(dbpath): conn=sqlite3.connect(dbpath) cur=conn.cursor() sql=’’’ create table test( id integer primary key autoincrement, link text, name varchar ) ’’’ cur.execute(sql) conn.commit() cur.close() conn.close()if __name__=='__main__': #程序執行入口 main()
到此這篇關于python爬蟲使用正則爬取網站的實現的文章就介紹到這了,更多相關python正則爬取內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備