Python爬蟲之教你利用Scrapy爬取圖片
Scrapy是一個(gè)適用爬取網(wǎng)站數(shù)據(jù)、提取結(jié)構(gòu)性數(shù)據(jù)的應(yīng)用程序框架,它可以通過定制化的修改來滿足不同的爬蟲需求。
使用Scrapy下載圖片項(xiàng)目創(chuàng)建首先在終端創(chuàng)建項(xiàng)目
# win4000為項(xiàng)目名$ scrapy startproject win4000
該命令將創(chuàng)建下述項(xiàng)目目錄。
項(xiàng)目預(yù)覽查看項(xiàng)目目錄
win4000 win4000 spiders __init__.py __init__.py items.py middlewares.py pipelines.py settings.py scrapy.cfg創(chuàng)建爬蟲文件進(jìn)入spiders文件夾,根據(jù)模板文件創(chuàng)建爬蟲文件
$ cd win4000/win4000/spiders# pictures 為 爬蟲名$ scrapy genspider pictures 'win4000.com'項(xiàng)目組件介紹
1.引擎(Scrapy):核心組件,處理系統(tǒng)的數(shù)據(jù)流處理,觸發(fā)事務(wù)。
2.調(diào)度器(Scheduler):用來接受引擎發(fā)出的請求, 壓入隊(duì)列中, 并在引擎再次請求的時(shí)候返回。由URL組成的優(yōu)先隊(duì)列, 由它來決定下一個(gè)要抓取的網(wǎng)址是什么,同時(shí)去除重復(fù)的網(wǎng)址。
3.下載器(Downloader):用于下載網(wǎng)頁內(nèi)容, 并將網(wǎng)頁內(nèi)容返回給Spiders。
4.爬蟲(Spiders):用于從特定的網(wǎng)頁中提取自己需要的信息, 并用于構(gòu)建實(shí)體(Item),也可以從中提取出鏈接,讓Scrapy繼續(xù)抓取下一個(gè)頁面
5.管道(Pipeline):負(fù)責(zé)處理Spiders從網(wǎng)頁中抽取的實(shí)體,主要的功能是持久化實(shí)體、驗(yàn)證實(shí)體的有效性、清除不需要的信息。當(dāng)頁面被Spiders解析后,將被發(fā)送到項(xiàng)目管道。
6.下載器中間件(Downloader Middlewares):位于Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應(yīng)。
7.爬蟲中間件(Spider Middlewares):介于Scrapy引擎和爬蟲之間的框架,主要工作是處理Spiders的響應(yīng)輸入和請求輸出。
8.調(diào)度中間件(Scheduler Middewares):介于Scrapy引擎和調(diào)度之間的中間件,從Scrapy引擎發(fā)送到調(diào)度的請求和響應(yīng)。
Scrapy爬蟲流程介紹Scrapy基本爬取流程可以描述為UR2IM(URL-Request-Response-Item-More URL):
1.引擎從調(diào)度器中取出一個(gè)鏈接(URL)用于接下來的抓取;
2.引擎把URL封裝成一個(gè)請求(Request)傳給下載器;
3.下載器把資源下載下來,并封裝成應(yīng)答包(Response);
4.爬蟲解析Response;
5.解析出實(shí)體(Item),則交給實(shí)體管道進(jìn)行進(jìn)一步的處理;
6.解析出的是鏈接(URL),則把URL交給調(diào)度器等待抓取。
頁面結(jié)構(gòu)分析首先查看目標(biāo)頁面,可以看到包含多個(gè)主題,選取感興趣主題,本項(xiàng)目以“風(fēng)景”為例(作為練習(xí),也可以通過簡單修改,來爬取所有模塊內(nèi)圖片)。
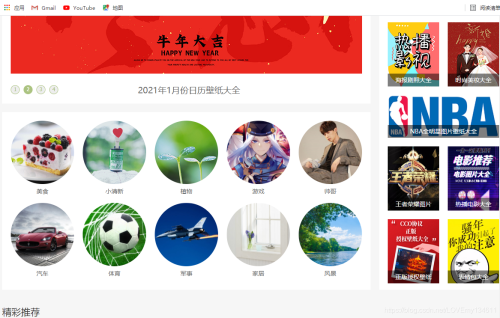
在“風(fēng)景”分類頁面,可以看到每頁包含多個(gè)專題,利用開發(fā)者工具,可以查看每個(gè)專題的URL,拷貝相應(yīng)XPath,利用Xpath的規(guī)律性,構(gòu)建循環(huán),用于爬取每個(gè)專題內(nèi)容。
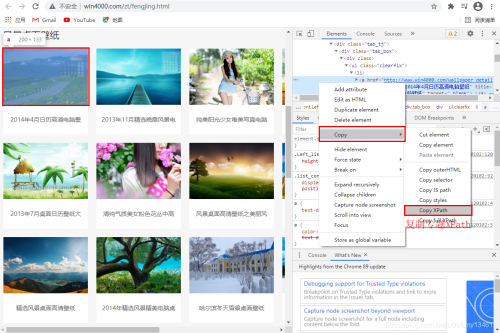
# 查看不同專題的XPath# /html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li[1]/a# /html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li[2]/a
利用上述結(jié)果,可以看到li[index]中index為專題序列。因此可以構(gòu)建Xpath列表如下:
item_selector = response.xpath(’/html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li/a/@href’)
利用開發(fā)者工具,可以查看下一頁的URL,拷貝相應(yīng)XPath用于爬取下一頁內(nèi)容。
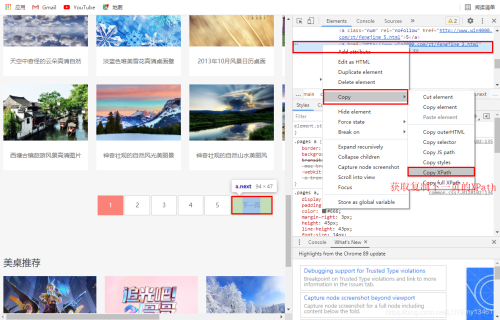
# 查看“下一頁”的XPath# /html/body/div[3]/div/div[3]/div[1]/div[2]/div/a[5]
因此可以構(gòu)建如下XPath:
next_selector = response.xpath(’//a[@class='next']’)
點(diǎn)擊進(jìn)入專題,可以看到具體圖片,通過查看圖片XPath,用于獲取圖片地址。
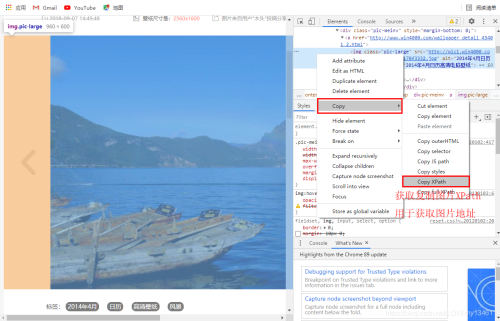
# 構(gòu)建圖片XPathresponse.xpath(’/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src’).extract_first()
可以通過標(biāo)題和圖片序列構(gòu)建圖片名。
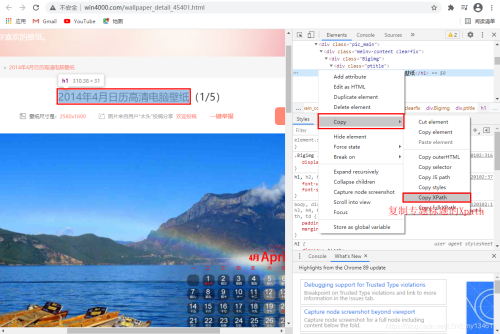
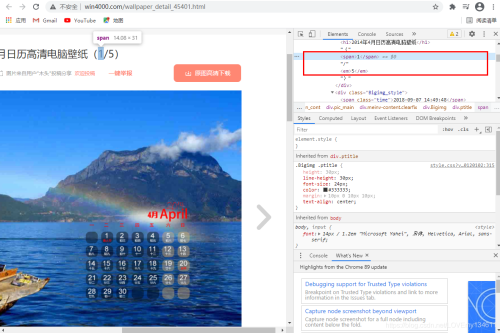
# 利用序號XPath構(gòu)建圖片在列表中的序號index = response.xpath(’/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()’).extract_first()# 利用標(biāo)題XPath構(gòu)建圖片標(biāo)題title = response.xpath(’/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()’).extract_first()# 利用圖片標(biāo)題title和序號index構(gòu)建圖片名name = title + ’_’ + index + ’.jpg’
同時(shí)可以看到,在專題頁面下,包含了多張圖片,可以通過點(diǎn)擊“下一張”按鈕來獲取下一頁面URL,此處為了簡化爬取過程,可以通過觀察URL規(guī)律來構(gòu)建每一圖片詳情頁的URL,來下載圖片。
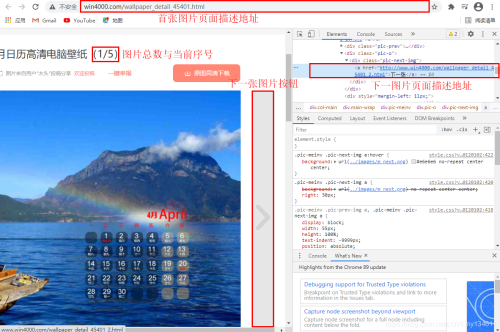
# 第一張圖片詳情頁地址# http://www.win4000.com/wallpaper_detail_45401.html# 第二張圖片詳情頁地址# http://www.win4000.com/wallpaper_detail_45401_2.html
因此可以通過首頁地址和圖片序號來構(gòu)建每一張圖片詳情頁地址。
# 第一張圖片詳情頁地址first_url = response.url# 圖片總數(shù)num = response.xpath(’/html/body/div[3]/div/div[2]/div/div[1]/div[1]/em/text()’).extract_first()num = int(num)for i in range(2,num+1): next_url = ’.’.join(first_url.split(’.’)[:-1]) + ’_’ + str(i) + ’.html’
定義Item字段(Items.py)
本項(xiàng)目用于下載圖片,因此可以僅構(gòu)建圖片名和圖片地址字段。
# win4000/win4000/items.pyimport scrapyclass Win4000Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() url = scrapy.Field() name = scrapy.Field()
編寫爬蟲文件(pictures.py)
代碼詳解見代碼注釋。
# win4000/win4000/spiders/pictures.pyimport scrapyfrom win4000.items import Win4000Itemfrom urllib import parseimport timeclass PicturesSpider(scrapy.Spider): name = ’pictures’ allowed_domains = [’win4000.com’] start_urls = [’http://www.win4000.com/zt/fengjing.html’]start_urls = [’http://www.win4000.com/zt/fengjing.html’] # cookie用于模仿瀏覽器行為 cookie={'t':'29b7c2a8d2bbf060dc7b9ec00e75a0c5','r':'7957','UM_distinctid':'178c933b40e9-08430036bca215-7e22675c-1fa400-178c933b40fa00','CNZZDATA1279564249':'1468742421-1618282415-%7C1618282415','XSRF-TOKEN':'eyJpdiI6Ik8rbStsK1Fwem5zR2YzS29ESlI2dmc9PSIsInZhbHVlIjoiaDl5bXp5b1VvWmdSYklWWkEwMWJBK0FaZG9OaDA1VGQ2akZ0RDNISWNDM0hnOW11Q0JTVDZFNlY4cVwvSTBjQlltUG9tMnFUcWd5MzluUVZ0NDBLZlJuRWFuaVF0U3k0XC9CU1dIUzJybkorUEJ3Y2hRZTNcL0JqdjZnWjE5SXFiNm8iLCJtYWMiOiI2OTBjOTkzMTczYWQwNzRiZWY5MWMyY2JkNTQxYjlmZDE2OWUyYmNjNDNhNGYwNDAyYzRmYTk5M2JhNjg5ZmMwIn0%3D','win4000_session':'eyJpdiI6Inc2dFprdkdMTHZMSldlMXZ2a1cwWGc9PSIsInZhbHVlIjoiQkZHVlNYWWlET0NyWWlEb2tNS0hDSXAwZGVZV05vTmY0N0ZiaFdTa1VRZUVqWkRmNWJuNGJjNkFNa3pwMWtBcFRleCt4SUFhdDdoYnlPMGRTS0dOR0tkdmVtVDhzUWdTTTc3YXpDb0ZPMjVBVGJzM2NoZzlGa045Qnl0MzRTVUciLCJtYWMiOiI2M2VmMTEyMDkxNTIwNmJjZjViYTg4MjIwZGIxNTlmZWUyMTJlYWZhNjk5ZmM0NzgyMTA3MWE4MjljOWY3NTBiIn0%3D' }def start_requests(self):'''重構(gòu)start_requests函數(shù),用于發(fā)送帶有cookie的請求,模仿瀏覽器行為'''yield scrapy.Request(’http://www.win4000.com/zt/fengjing.html’, callback=self.parse, cookies=self.cookie) def parse(self,response): # 獲取下一頁的選擇器next_selector = response.xpath(’//a[@class='next']’)for url in next_selector.xpath(’@href’).extract(): url = parse.urljoin(response.url,url) # 暫停執(zhí)行,防止網(wǎng)頁的反爬蟲程序 time.sleep(3) # 用于爬取下一頁 yield scrapy.Request(url, cookies=self.cookie)# 用于獲取每一專題的選擇器item_selector = response.xpath(’/html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li/a/@href’)for item_url in item_selector.extract(): item_url = parse.urljoin(response.url,item_url) #print(item_url) time.sleep(3) # 請求專題頁面,并利用回調(diào)函數(shù)callback解析專題頁面 yield scrapy.Request(item_url,callback=self.parse_item, cookies=self.cookie)def parse_item(self,response):'''用于解析專題頁面'''# 由于Scrapy默認(rèn)并不會(huì)爬取重復(fù)頁面,# 因此需要首先構(gòu)建首張圖片實(shí)體,然后爬取剩余圖片,# 也可以通過使用參數(shù)來取消過濾重復(fù)頁面的請求# 首張圖片實(shí)體item = Win4000Item()item[’url’] = response.xpath(’/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src’).extract_first()index = response.xpath(’/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()’).extract_first()item[’name’] = response.xpath(’/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()’).extract_first() + ’_’ + index + ’.jpg’yield itemfirst_url = response.urlnum = response.xpath(’/html/body/div[3]/div/div[2]/div/div[1]/div[1]/em/text()’).extract_first()num = int(num)for i in range(2,num+1): next_url = ’.’.join(first_url.split(’.’)[:-1]) + ’_’ + str(i) + ’.html’ # 請求其余圖片,并用回調(diào)函數(shù)self.parse_detail解析頁面 yield scrapy.Request(next_url,callback=self.parse_detail,cookies=self.cookie) def parse_detail(self,response):'''解析圖片詳情頁面,構(gòu)建實(shí)體'''item = Win4000Item()item[’url’] = response.xpath(’/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src’).extract_first()index = response.xpath(’/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()’).extract_first()item[’name’] = response.xpath(’/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()’).extract_first() + ’_’ + index + ’.jpg’yield item
修改配置文件settings.py
修改win4000/win4000/settings.py中的以下項(xiàng)。
BOT_NAME = ’win4000’SPIDER_MODULES = [’win4000.spiders’]NEWSPIDER_MODULE = ’win4000.spiders’# 圖片保存文件夾IMAGES_STORE = ’./result’# Crawl responsibly by identifying yourself (and your website) on the user-agent# 用于模仿瀏覽器行為USER_AGENT = ’Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:87.0) Gecko/20100101 Firefox/87.0’# Obey robots.txt rulesROBOTSTXT_OBEY = False# Configure a delay for requests for the same website (default: 0)# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docs# 下載時(shí)延DOWNLOAD_DELAY = 3# Disable cookies (enabled by default)# 是否啟用CookieCOOKIES_ENABLED = True# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = { ’win4000.pipelines.Win4000Pipeline’: 300,}
修改管道文件pipelines.py用于下載圖片
修改win4000/win4000/pipelines.py文件。
from itemadapter import ItemAdapterfrom scrapy.pipelines.images import ImagesPipelineimport scrapyimport osfrom scrapy.exceptions import DropItemclass Win4000Pipeline(ImagesPipeline): def get_media_requests(self, item, info):# 下載圖片,如果傳過來的是集合需要循環(huán)下載# meta里面的數(shù)據(jù)是從spider獲取,然后通過meta傳遞給下面方法:file_pathyield scrapy.Request(url=item[’url’],meta={’name’:item[’name’]}) def item_completed(self, results, item, info):# 是一個(gè)元組,第一個(gè)元素是布爾值表示是否成功if not results[0][0]: with open(’img_error_name.txt’,’a’) as f_name:error_name = str(item[’name’])f_name.write(error_name)f_name.write(’n’) with open(’img_error_url.txt’,’a’) as f_url:error_url = str(item[’url’])f_url.write(error_url)f_url.write(’n’)raise DropItem(’下載失敗’)return item # 重命名,若不重寫這函數(shù),圖片名為哈希,就是一串亂七八糟的名字 def file_path(self, request, response=None, info=None):# 接收上面meta傳遞過來的圖片名稱filename = request.meta[’name’]return filename
編寫爬蟲啟動(dòng)文件begin.py
在win4000目錄下創(chuàng)建begin.py
# win4000/begin.pyfrom scrapy import cmdlinecmdline.execute(’scrapy crawl pictures’.split())最終目錄樹 win4000 begin.py win4000 spiders __init__.py pictures.py __init__.py items.py middlewares.py pipelines.py settings.py scrapy.cfg項(xiàng)目運(yùn)行
進(jìn)入begin.py所在目錄,運(yùn)行程序,啟動(dòng)scrapy進(jìn)行爬蟲。
$ python3 begin.py爬取結(jié)果
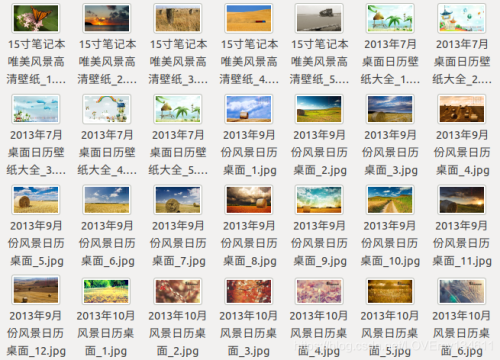
本項(xiàng)目僅用于測試用途。Enjoy coding.
到此這篇關(guān)于Python爬蟲之教你利用Scrapy爬取圖片的文章就介紹到這了,更多相關(guān)python中用Scrapy爬取圖片內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. JS中6個(gè)對象數(shù)組去重的方法2. Java commons-httpclient如果實(shí)現(xiàn)get及post請求3. 資深程序員:給Python軟件開發(fā)測試的25個(gè)忠告!4. 一文帶你徹底理解Java序列化和反序列化5. PHP程序員簡單的開展服務(wù)治理架構(gòu)操作詳解(二)6. PHP利用curl發(fā)送HTTP請求的實(shí)例代碼7. Python基于requests庫爬取網(wǎng)站信息8. vscode運(yùn)行php報(bào)錯(cuò)php?not?found解決辦法9. PHP laravel實(shí)現(xiàn)導(dǎo)出PDF功能10. python中文本字符處理的簡單方法記錄
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備