文章詳情頁
python - 基于scrapy-redis的分布式爬蟲運(yùn)行的時(shí)候不能正常運(yùn)行 遇到的問題如下截圖所示
瀏覽:214日期:2022-08-03 11:20:00
問題描述
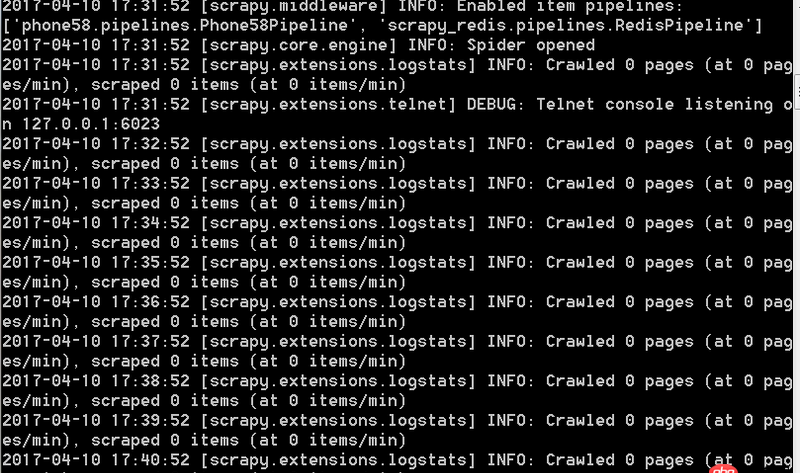
爬蟲運(yùn)行時(shí)一直是這樣的每一分鐘出現(xiàn)一條這樣的信息,無限循環(huán)。不能爬取下來數(shù)據(jù)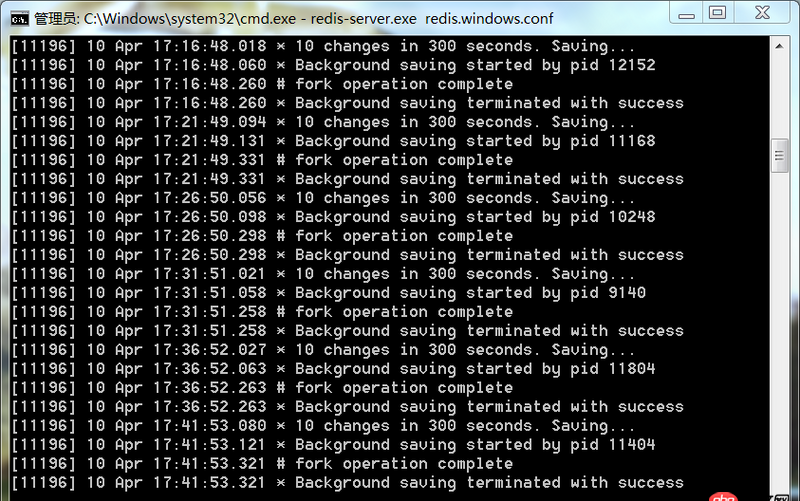
這是redis服務(wù)端的顯示
這樣是什么問題,望有高手可以為我解惑,謝謝。
問題解答
回答1:使用scrapy_redis,你要去投放url讓spider去爬取,你投放了嗎?比如
redis-cli lpush myspider:start_urls http://google.com
上一條:python3.x - python中的虛擬環(huán)境怎樣設(shè)置一直處于激活狀態(tài)下一條:python - scrapy-redis爬蟲運(yùn)行是連接redis數(shù)據(jù)庫連接錯誤
相關(guān)文章:
1. javascript - immutable配合react提升性能?2. 如何設(shè)置一個(gè)無限循環(huán)并打破它。(Java線程)3. DADB.class.php文件的代碼怎么寫4. javascript - sublime快鍵鍵問題5. php對mysql提取數(shù)據(jù)那種速度更快6. macos - 如何徹底刪除mac自帶的apache和php7. docker 17.03 怎么配置 registry mirror ?8. mysql事務(wù)回滾定位9. 實(shí)現(xiàn)bing搜索工具urlAPI提交10. css - 移動端字體設(shè)置問題
排行榜

熱門標(biāo)簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備