文章詳情頁
python - 使用scrapy框架爬百度圖片被墻
瀏覽:216日期:2022-06-30 14:19:37
問題描述
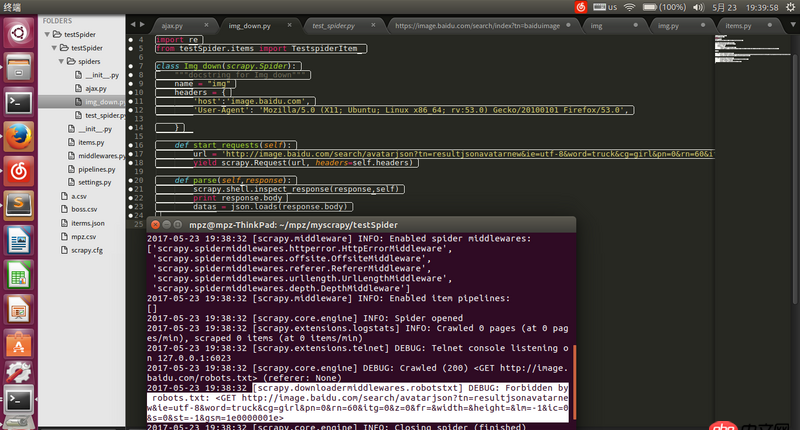
請求地址url是通過firefox查看得到的json的地址,用瀏覽器可以打開,但是用scrapy爬的時候就被ban了求解決辦法。
https://image.baidu.com/searc...
問題解答
回答1:在 settings.py 將 ROBOTSTXT_OBEY = False 試試。
回答2:不要加hearders試試
回答3:贊成樓上,如果還會被墻。可采用scrapy+selenium+phantomjs的方式。
相關文章:
1. javascript - ionic1的插件如何遷移到ionic2的項目中2. python小白 自學看書遇到看不懂的地方3. javascript - immutable配合react提升性能?4. javascript - 在vue項目中遇到的問題:DOMException5. php對mysql提取數據那種速度更快6. shell - mysql更新錯誤7. javascript - vue中使用prop傳遞數據問題8. python - 在github上看到一個基于卷積神經網絡提高圖片分辨率的小項目waifu2x??9. 如何設置一個無限循環并打破它。(Java線程)10. 網頁爬蟲 - 如何使用使用java抓取信息并制作一個排名系統?
排行榜

 網公網安備
網公網安備