python - 爬取微信公眾號(hào)文章需要輸入驗(yàn)證碼問(wèn)題
問(wèn)題描述
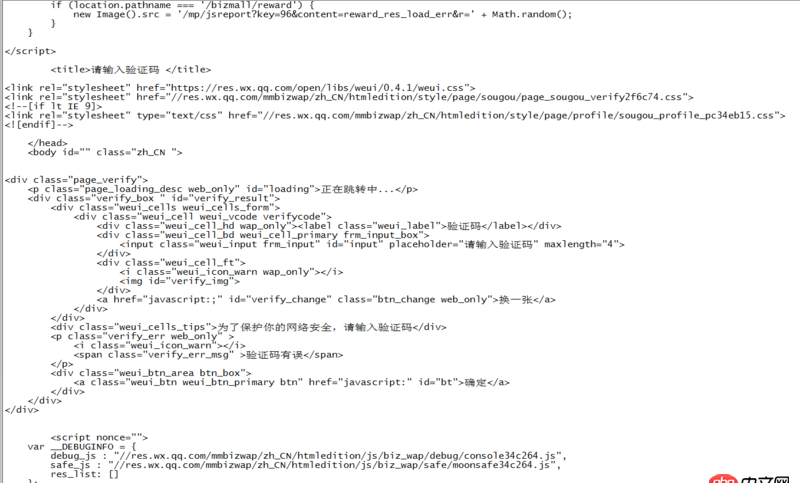
一開(kāi)始請(qǐng)求是正常的,請(qǐng)求多了就返回這個(gè)網(wǎng)頁(yè),提示要驗(yàn)證。現(xiàn)在加了代理,加了header也都是返回這個(gè)。不知道有沒(méi)有什么辦法能繞過(guò)這個(gè)驗(yàn)證,或者后臺(tái)可以模擬驗(yàn)證?有沒(méi)有大神遇到類(lèi)似的問(wèn)題?簡(jiǎn)單貼下請(qǐng)求的代碼
url = 'https://mp.weixin.qq.com/profile?src=3×tamp=1498555925&ver=1&signature=mFCwcLO9hTwe*Js7TGQ457olpvr1d85gJSnVLyFgtYkX072FzolMsfonBR6Av2BOSe2kJ8z-m25ecftpvQ-edw==' req = urllib2.Request(url) proxy='218.56.132.155:8080'//嘗試了各種代理ip,這邊先寫(xiě)死 opener = urllib2.build_opener(urllib2.ProxyHandler({’http’:proxy})) urllib2.install_opener(opener) req.add_header('User-Agent', 'Mozilla/5.0') req.add_header('Accept-Language', 'zh-cn,zh;q=0.5') req.add_header(’Accept-encoding’, ’gzip,deflate’) resp = urllib2.urlopen(req) content = resp.read() print content
問(wèn)題解答
回答1:去搜狗搜索去爬微信吧
回答2:沒(méi)爬過(guò)微信,不過(guò)建議使用 requests 推薦參考下wechatsogou
相關(guān)文章:
1. 如何設(shè)置一個(gè)無(wú)限循環(huán)并打破它。(Java線程)2. 網(wǎng)頁(yè)爬蟲(chóng) - 如何使用使用java抓取信息并制作一個(gè)排名系統(tǒng)?3. mysql - 在log日志中已知用戶的某一步操作,如何獲取其上一步操作?4. php對(duì)mysql提取數(shù)據(jù)那種速度更快5. shell - mysql更新錯(cuò)誤6. javascript - sublime快鍵鍵問(wèn)題7. javascript - immutable配合react提升性能?8. python小白 自學(xué)看書(shū)遇到看不懂的地方9. macos - 如何徹底刪除mac自帶的apache和php10. DADB.class.php文件的代碼怎么寫(xiě)
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備